ユーザーが商品を検索する | ドメイン駆動設計ハンズオン
Prev: 管理者が商品を登録する
フィーチャーツリーとユースケース
フィーチャーツリーは以下の通りでした。
- 決済機能
- ユーザー情報変更
- 商品カタログ
- 商品の検索
- (実装済み)商品管理
- 注文
- ショッピングカート
- 注文受付機能
- 配送状態確認
ユースケースは以下の通りです。
- (実装済み)管理者が商品を登録する
- ユーザーが商品を検索する
- ユーザーがショッピングカートに商品を追加する
- ユーザーがショッピングカートの中身を確認する
この章では「ユーザーが商品を検索する」ユースケースで、「商品カタログ」グループの「商品の検索」機能を実装していきます。
機能要求を考える
「ユーザーが商品を検索する」ユースケースのデータモデリングをする前に機能要求の詳細を詰める必要があるでしょう。つまり「検索」とは何かです。スクラムならユーザーストーリーとして「ユーザーが商品を検索する」というPBIが作成されスプリントに入る頃には、そのPBIの説明に以下のようなことが書かれていることでしょう。
- 検索条件
- 商品名:部分一致で検索可能
- 価格:ユーザーの任意入力で上限下限の両方または片方を指定してその範囲で検索可能
- 画面に出力する内容
- 20商品ずつ表示
- 1商品に以下の情報を表示
- 商品名:30文字を超える場合は31文字以上を
…に置き換え(トランケート) - 価格
- 商品名:30文字を超える場合は31文字以上を
本来なら画面イメージなども用意されレイアウトなども指定されると思いますが、ハンズオンなので省略です。
データモデリングの実施
今回の場合は比較的単純です。商品の一覧を保持するコンテナと商品名と価格を持った商品Entityがあるだけです。
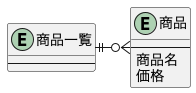
ここで、前回(管理者が商品を登録する)で作ったProduct Aggregateを再利用したら良いのではないかと思えます。しかし、前回作成したProduct Aggregateにはvalid?メソッドが実装されています。valid?メソッドはバリデーションのメソッドであり、今回のユースケース「ユーザーが商品を検索する」は出力するだけなので必要のないメソッドです。また、今回のユースケースでは商品名のトランケートが必要ですが、前回作成したProduct Aggregateにとっては不要な処理です。
このように、似ているからとか再利用できそうだからと使い回すのはよくありません。上記のように保存用の処理と出力用の処理が1つのクラスにあると保存と出力の2つの責務を1つのクラスに持つことになります。これを単一責任の原則に違反した状態といいます。保存と出力というわかりやすい例ですが、双方が出力しかしないのだとしても責務が異なるなら分けるようにしてください。
なお、特に保存と出力のAggregateを分けることをCQRSと呼ぶことがあります。
上記の説明を読んで、保存用のAggregateと出力用のAggregateを分けるのがCQRSなら「当たり前では?」と思うかもしれません。というか、私自身思います。
別の文脈のCQRSの説明だとイベントソーシングなどが関わってきます。イベントソーシングは、いつ何があったというイベントを記録するデータベースを用意して、保存はイベントの記録を行い、出力はイベントの畳み込みを行った結果を返すというものです。例をあげましょう。
イベントとして以下が記録されています。
- 5月1日 9:41 商品 id: 1, name: 商品A, price: 1000円 で新規登録
- 5月1日 9:42 商品 id: 2, name: 商品B, price: 2000円 で新規登録
- 5月1日 9:43 商品 id: 1 を price: 1200円 に更新
- 5月2日 7:43 商品 id: 1 を name: 商品X に更新
- 5月2日 7:45 商品 id: 2 を name: 商品BBB に更新
- 5月9日 6:00 商品 id: 1 を削除
RDBだったら、5月10日時点でid: 1の商品は削除済みで値段を知ることはできません(リストアすれば別ですが)。イベントソーシングならイベントを遡れば商品Aの変化をみることができます。このようにイベントソーシングは監査ログを目的として設計されることもあります。しかし、イベントソーシングはその時々での変化は保存しますが、最終的な結果を保存するわけではありません。そのため、id: 2の商品が最終的にどういう状態なのかしるためには、すべてのイベントを畳み込み(積算)する必要があります。
当然、検索するたびにそんなことをしていたら非効率極まりなく、毎分数万イベント登録されるようなイベントソーシングシステムだったらアキレスとカメのような状態になるでしょう(畳み込みが終わる頃には新しいイベントが積まれているだろうという意味)。
そのため、保存処理はイベントソーシングで行い、イベントソーシングとは別に畳み込みをすませたデータベースを読み込みのために用意するということが行われます。このように、保存と読み込みでデータベースが別れるため、自然とAggregateも別れた状態になります。イベントソーシングに限りませんが、このようにAggregateが永続化されるデータベースと読み込まれるデータベースが異なり、Aggregateも異なっている状態をCQRSと呼ぶことがあります。
個人的には、単にAggregateを更新系と参照系でわけるだけならCQRSと呼ぶ必要はないだろうと思います。ただ、この感性は私がWEBエンジニアであるからの可能性もあり、Windowsアプリのようなオブジェクトが長時間メモリ上に存在することが前提となるようなプログラムだったら、腹落ちするのかもしれません。
Aggregateの実装
ではAggregateを実装していきます。今回の場合、商品一覧は配列でも良いのですが、クラスとして実装してみましょう。Module(Package)は商品カタログの商品検索なのでProductCatalog::ProductSearchとします。
# 商品一覧
class ProductCatalog::ProductSearch::ProductList
attr_reader :products
# 引数のproductsは以下のような配列
# [{ name: '商品名A', price: 10000 }, { ... }]
def initialize(products)
# 引数の配列の1要素ごとにProductのインスタンスを作成して配列を作る
@products = products.map do |product|
ProductCatalog::ProductSearch::Product.new(
product[:name], product[:price]
)
end
end
end
class ProductCatalog::ProductSearch::Product
attr_reader :name, :price
def initialize(name, price)
@name = name
@price = price
end
end
商品名は「30文字を超える場合は31文字以上を…に置き換え(トランケート)」という制限があるのでこれを実装します。
class ProductCatalog::ProductSearch::Product
# getterからnameを削除
attr_reader :price
def initialize(name, price)
@name = name
@price = price
end
# getterの代わりにトランケートした文字列を返すメソッドを実装
def name
return @name if 30 < @name.length
@name[0..29] + '…'
end
end
Repositoryの実装
今回は前回と比べて多少複雑なRepositoryの実装になります。検索処理とインピーダンスミスマッチの解消でフレームワークの機能を多用するのが理由です。
検索条件は以下の通りでした。
- 検索条件
- 商品名:部分一致で検索可能
- 価格:ユーザーの任意入力で上限下限の両方または片方を指定してその範囲で検索可能
class ProductCatalog::ProductSearch::ProductListRepository
def search(name: '', from_price: nil, to_price: nil, page: nil)
products = Product
products = base.where('name like ?', "%#{name}%") if name.present?
products = base.where('? <= price', from_price) if from_price.present?
products = base.where('price <= ?', to_price) if to_price.present?
products = products.page(page).per(20)
# ActiveRecordの配列から以下の形式のhashの配列に変換している
# [{ name: '商品名A', price: 10000 }, { ... }]
product_hash_list = products.select(:id, :name)
.map(&:attributes)
.map(&:symbolize_keys)
ProductCatalog::ProductSearch::ProductList.new(product_hash_list)
end
end
Railsエンジニアならお察しの通り、上記のコードはKaminariというGem(ライブラリ)を使ったコードです。View上でページネーション( <最初 1 2 3 ... 10 最後> のようなUI)を表示するのに便利なGemです。しかし、View上でこのUIを出すには上記のコードでいえば products.page(page).per(20) の戻り値をViewから参照できる必要があります。
RepositoryはAggregateを受け取って永続化、あるいは永続化したデータからAggregateを復元する役割の設計パターンです。ただ、かといってそこにこだわって、実装上不都合が出てしまうならそれは本末転倒です。なので、私としては、Aggregateと一緒に複数値返すとか、あるいはインスタンス変数に入れて別途取得できるようにするなどの方法をとるのが良いと考えています。
# AggregateのインスタンスとKaminariのインスタンスの両方を返す例
def search(...)
....
return [ProductList.new(...), products.page(page).per(20)]
end
# インスタンス変数に入れて別途取得できるようにする例
attr_reader :products_pagination
def search(...)
...
@products_pagination = products.page(page).per(20)
...
end
ApplicationServiceの実装
では最後に「ユーザーが商品を検索する」ユースケースに対応するApplicationServiceを実装していきます。といっても、Repositoryを呼び出して、生成したProductListを返すだけです。
# ユーザーが商品を検索する
class UserSearchProduct
def perform(name: '', from_price: nil, to_price: nil, page: nil)
ProductCatalog::ProductSearch::ProductListRepository.new.search(
name: name, from_price: from_price, to_price: to_price, page: page
)
end
end
ここで、いくつか選択肢が出てきます。上記はそのままDomainModelをApplicationServiceの呼び出し元(Controllerやバッチ、rails consoleなど)に返してしまっています。これをレイヤまたぎとして嫌うなら、DTOを定義したりJSON的なHashと配列のデータにして受け渡すということもできます。できますが、おそらくそれはオーバーエンジニアリングです。そうすることにどういうメリットがあるのか考えてください。そして、そのメリットを本当に享受できるのかも考えてください。その上で、バケツリレーするためだけのコードが増えること、それに伴う実装コストの増加と可読性の低下などがペイするだけのメリットが享受できるのかを考えてください。
Next: 管理者がセール情報を登録する