モデリング手法 | これで理解できるドメイン駆動設計!
Prev: ドメイン駆動設計の核心
ドメインモデルを明らかにするためのモデリング手法
さて、ここまでドメイン駆動設計とはで「ドメイン駆動設計」とはドメインを分析してドメインモデルを明らかにしドメインモデルが実装に反映されるように設計を行う設計手法だと説明し、ドメイン駆動設計の戦術的設計とはでドメインモデルを実装に反映するための設計パターンを説明してきました。
ここでようやく、肝心のドメインを分析してドメインモデルを明らかにするモデリング手法について説明します。しかし問題がいくつかあります。
第一にDDDとしてスタンダードなモデリング手法はありません。エリック・エヴァンスのドメイン駆動設計にはこういうモデリング手法でモデリングしていこうというような話は全く書かれていないのです。
第二にモデリング手法がいくつもあるということです。どのモデリング手法を使うべきか考えねばなりません。
ただ、海外ではイベントストーミングというモデリング手法が主流あるいは人気のようです。
色々あるモデリング手法
提唱されているモデリング手法は色々存在します。ユースケース実践ガイド―効果的なユースケースの書き方に書かれているICONIXとか、モデルベース要件定義テクニックやRDRA2.0 ハンドブック: 軽く柔軟で精度の高い要件定義のモデリング手法に書かれているRDRAなど。
これは本当に個人的な趣味嗜好による判断ですが、こういう特定の手法を学ぶ気は起きません。
ちょっと話はそれますが、Salesforceの導入などをするエンジニアの年収は高いそうですが、そういうエンジニアはSalesforceのコンサル企業かユーザー企業にしか転職できません。仮にSalesforceが素晴らしいものだと言って未導入の企業に導入しようとするなら、いろんな人を巻き込んでSalesforceの使い方を覚えてもらう必要があります。要するに言いたいことはSalesforceのエンジニアはキャリアをSalesfoceにベンダーロックインされるということです。
モデリング手法も同じで、ICONIXに詳しくなり良いものだと思ってモデルを作成したとしても、周りの人が読めるようになっていなければ意味がありません。モデルはビジネスサイドやプロダクトオーナーも読むものなので、それらの人もICONIXに詳しくなってもらう必要があります。転職したい場合、ICONIXを導入している企業を選り好みするか、学んできたICONIXの手法を捨てるかしなければなりません。
Salesforceの例に準えるならAWSのようにデファクトスタンダードでどこに行ってもメインストリームとして使っているなら問題はないでしょうが、ICONIXもRDRAもそうではありません。
もう一つ理由があります。これはUMLでも同じですが特定の書き方を覚えるための学習コストが必要になります。また、書くときに書式を守るためにオーバーヘッドが必要であり、読むときにも書式の意味を思い出すためのオーバーヘッドが必要になります。さらに悪いことに書式が定まっていて、その書式を学ぶ必要があるという状態になると、書式を守ることに目的がすげ変わってしまいます。
モデルは何を書くかと何が書かれているか読み手に伝わるかが重要なのであり、どのように書くのかということはどうでも良いことです。それゆえに、モデリング手法はライトウェイトで最低限のものにして、モデリング手法に知識がない人が読んでも意味を自分で補完してその資料だけで理解できる状態にできるものが良いと考えています。
ひどいことをいうと、いずれにせよ同じドメインを分析してソフトウェアを作るのだから必要な要素を分析できていれば書式が違えど含まれる内容は同じはずなのです。だから、どう書くかはどうでもよく、何を分析しなければならないかの方がはるかに重要なのです。
最近流行りのイベントストーミング
海外ではイベントストーミングという手法が人気らしく、日本国内でも話題に上がるようになった手法です。書籍においては要件最適アーキテクチャ戦略の3章 イベントファーストの実験と発見で解説されています。
イベントストーミングはコマンドとイベントという2つの概念が核のモデリング手法で、システムの全体像を明らかにするために行われるグループワークです。大きい模造紙を壁に貼って、どういうコマンドやイベント、ポリシーなどがあるか、そしてそれらがどういう関連をもち、どういう順序になっているかなどを明らかにしていくことが目的になります。
実際には付箋を使ってコマンドやイベントを識別していくのですが、ECサイトを例に文章で書くと以下のような感じになります。
- ユーザー(ロール)が商品を注文する(コマンド)
- 在庫確保(イベント)
- 請求発生(イベント)
- 配送手配(イベント)
- 配送計画決定(ポリシー):どの倉庫から送るか決める
- 倉庫作業員(ロール)が商品を発送する(コマンド)
- 在庫数の変化(イベント)
- 配達の確定(イベント)
名前の通りイベントがモデリングの主役であり、マイクロサービスやイベントソーシングを行う場合には役に立つ手法なのかもしれません。
ただ、あくまで全体像を俯瞰的に把握するためのグループワークです。コマンドやイベント、ポリシーといった個々の付箋の詳細を詰めることを目的としていません。そのため、イベントストーミングを実施したからといって即座にDomainModelの実装に入れるというわけではありません。
ドメイン駆動設計を行う上では、ドメインを分析してドメインモデルを明らかにしドメインモデルが実装に反映されるように設計を行う設計手法の「ドメインの分析」は行っているのですが、「ドメインモデルを明らかにする」という点で不十分なのです。イベントストーミングを行った上で、別途さらにコマンドやイベント、ポリシーの詳細を分析することが必要になります。
イベントストーミングについての詳しい解説は要件最適アーキテクチャ戦略を参照してください。
付け加えておくと、イベントもまたドメインを分析した結果モデリングされたものであり、ドメインモデルであるということです。イベントをモデリングするのであれば、イベントを実装したDomainModelを作るということも考える必要が出てきます。
私がおすすめする手法
私がおすすめするのは古典的なモデリング手法です。それはフィーチャーツリー、ユースケース(ユーザーストーリー)、データモデリング、データディクショナリ、ビジネスルール、状態遷移図です。これらの手法はMicrosoft Pressから出版されているソフトウェア要求 第3版にすべて載っています。そして、それぞれ戦術的設計の設計パターンに対応づけることができます。
| レイヤ | DomainModel | モデリング手法 |
|---|---|---|
| ユースケース(アプリケーション)レイヤ | ApplicationService | ユースケース(ユーザーストーリー) |
| ドメインレイヤ | DomainService | ユースケース(ユーザーストーリー) |
| ドメインレイヤ | Module(Package) | フィーチャーツリー |
| ドメインレイヤ | Aggregate | データモデリング |
| ドメインレイヤ | Entity | データモデリング |
| ドメインレイヤ | ValueObject | データディクショナリ、状態遷移図 |
| ドメインレイヤ | Specification | ビジネスルール |
私がこれらの手法をおすすめするのには、もちろん理由があります。
1つ目はモデリング手法をそのまま戦術的設計の設計パターンに対応づけることができる点です。ドメイン駆動設計を実践する上で起こる問題は、設計パターンに基づいて実装する元となる物がわからないというのがあります。せいぜい、ユースケース(ユーザーストーリー)とクラス図を作成するぐらいのため、どれがEntityでどれがValueObject、Specificationなのかの区別ができない状態に陥ります。上記の通り、モデリング手法と設計パターンの対応づけができているため、そう言った事態に陥らないというメリットがあります。
2つ目は枯れた手法であり、広く使われている手法が多い点です。ユースケース(ユーザーストーリー)、状態遷移図はあなたが想像しているものそのものです。データモデリングとデータディクショナリはRDBのテーブル設計をしたことがあれば、無意識にやっている活動のはずです。それをドメインモデルの分析として行うというだけの話です。
3つ目は特定の方法論の手法ではないという点です。UMLのような広く使われている記述方法かフリーフォーマットです。何か新しく書式を覚える学習コストが少なく済む可能性が高いのです。
4つ目は各モデリング手法の目的がはっきりしているという点です。何の目的で書くのか、書かれたのかがはっきりしているため、モデリング手法に詳しくない人でも読み取りやすいというのがあります。また、目的からはずれさえしなければ書式にこだわる必要性も薄いため、モデリング手法に詳しくない人のために簡略的な図にしたり補足情報を記述したりと言ったこともできるということです。
ここで勘違いしてほしくないのは、データモデリング、データディクショナリはテーブル設計のための手法ではないということです。「テーブル設計の手法であるデータモデリング、データディクショナリをドメインモデルの分析に利用する」ではなく「データモデリング、データディクショナリという手法があって、もっぱらテーブル設計の時に使われる」という理解が正しいのです。テーブル設計と独立した手法なので、ドメインモデルの分析においてもモデリング手法として利用できるということです。
データモデリングではクラス図またはER図を利用してドメインモデルを作成します。ここでも勘違いされがちなのは、ER図もまたテーブル設計のためのダイアグラムではないということです。ER図(Entity Relationship Diagram: 実体関連図)はエンティティ(RDBでいうならテーブル)にどのような属性(RDBでいうならカラム)があり、エンティティ同士がどういう関連を持つか(RDBでいうJOIN)を表現する図でしかないということです。Aggregateに対応するドメインモデルをモデリングするのにも使えるのです。
各モデリング手法の解説
フィーチャーツリー
フィーチャーツリーは、プロダクトのフィーチャーを論理的なグループにわけ、各フィーチャーをより詳細なレベルに階層的に分割して、ビジュアルに示した図である (中略)
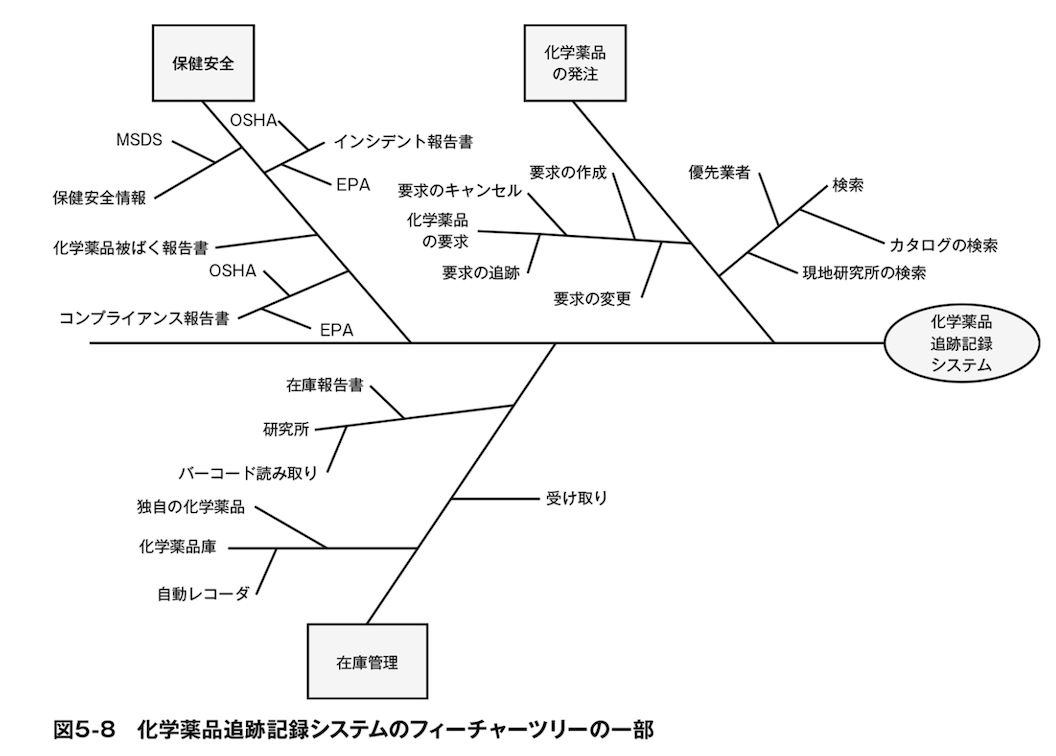
ソフトウェア要求 第3版 第5章 ビジネス要求の確立 5.3.3 フィーチャーツリー
フィーチャーツリーは機能を分類し作ろうと考えているシステムを俯瞰的に見ることを目的に作成します。
フィーチャーツリーはModule(Package)に対応させることができます。フィーチャーツリーを作成しModule(Package)としてDomainModelに反映させることで、AggregateやValueObject、Specificationを整理することができます。
転職サイトを例にするなら以下のようなフィーチャーツリーを考えることができます。
- マッチング機能
- 求職者情報登録機能
- 求人情報機能
- 下書き登録機能
- 登録機能
- 応募終了機能
- 応募採用機能
- 求職者応募機能
- 企業スカウト機能
フィーチャーツリーは機能を分類し階層構造に整理していくモデリング手法のため、開発チームが結成される前か結成した最序盤に、ビジネスサイドやプロダクトオーナーが中心となって作成することをおすすめします。エンジニアやステークホルダーにとってまだ見ぬサービスの全体像を窺い知ることのできる資料となるからです。
また当然ながら開発が進むにつれ新しい知識が獲得されフィーチャーツリーの形が変容していきます。そのため、折に触れてフィーチャーツリーを見直し、それに合わせてコード上のModule(Package)も変えていくことが重要になります。
これは戦略的設計の話になりますが、一番大きなカテゴライズ、引用した図でいうところの「保険安全」や「化学薬品の発注」は境界づけられたコンテキストの候補になりうるでしょう。
ユースケース(ユーザーストーリー)
ユースケースは、システムの振る舞いに関する利害関係者間の契約を表現するものです。ユースケースでは、システムが1人の利害関係者(主アクターと呼びます)の要求に対して反応するときの、さまざまな状況におけるシステムの振る舞いを記述します。
ユースケース実践ガイド―効果的なユースケースの書き方 p.9
ユーザーストーリーは、アジャイル型プロジェクトで使用されており、「新しい能力を望む人、通常はシステムのユーザーまたは顧客の観点から、フィーチャーを簡潔に記述したもの」である
ソフトウェア要求 第3版 第8章 ユーザー要求の理解 8.1 ユースケースとユーザーストーリー
ユースケースにせよユーザーストーリーにせよ、実行したり要求したりする主体(主アクターあるいはユーザークラス)がいて、その主体が実行できる機能が記述されます。
転職サイトを例にユースケースを書くなら以下のようになります。
# 求人を公開し採用するユースケース(これで1つのユースケース)
採用担当者は求人を登録する
運営者は求人に規約違反がないか確認し公開する
求職者は求人に応募する
採用担当者は応募を確認し書類選考を行い結果を通知する
ユーザーストーリーなら以下のようになります。
# 求人を公開し採用するまでのユーザーストーリー(1つ1つが個々のユーザーストーリー)
採用担当者は事業拡大のために人を追加したいので、求人を登録したい
運営者は規約違反の求人は掲載したくないので、求人を確認してから公開したい
求職者は新しい仕事につきたいので求人に応募する
採用担当者は選考をすすめたいので、応募を確認し書類選考を行い結果を応募者に通知したい
どちらが良いかは本書の主題ではないので省略します。なお、ユースケースの例は簡略形式で、もっと形式ばった書式も存在します。
ポイントなのは、上記の例一行一行がApplicationServiceと対応づけることができるということです。
# 採用担当者は求人を登録する
RecruiterRegisterJobOpening
# 運営者は求人に規約違反がないか確認し公開する(※簡略的なクラス名にしている)
AdministratorReviewJobOpening
# 求職者は求人に応募する
JobSeekerApplyToJobOpening
ユースケース(ユーザーストーリー)はApplicationServiceに対応し「アプリケーションの機能としてのエンドポイント」と言っている通り、ここを出発点としてユースケース(ユーザーストーリー)を実現するために必要なドメインモデルを分析していくことになります。そしてそのドメインモデルの分析のためにデータモデリング、データディクショナリ、ビジネスルール、状態遷移図を利用するというわけです。
アクターというのは「採用担当者」とか「運営者」とか「求職者」のようなユースケースやユーザーストーリーを実行する主体のことです。人に限らずシステムの場合もあります。このアクターをApplicationServiceの名前につけるかつけないかという選択があります。
選択があるというか、一般的(?)にはつけないようです。色々な書籍を確認していますがつけている例を見たことがありません。しかし、私はつけるべきだと思っています。
いうまでもなく誰が実行するユースケースなのかというのはドメイン知識です。アクターをApplicationServiceの名前につけないということは、ドメイン知識を欠損させていることに他なりません。
また、採用担当者と求職者のように主要なユーザー分類がいくつかある場合、注目しているApplicationServiceがどちらのための機能なのかクラス名を見るだけでわかるというのは、可読性の面で大きなアドバンテージです。例えば、採用担当者が実行するはずのControllerで AdministratorReviewJobOpening が呼ばれていたら、相当まずいことになっているのはひと目でわかります。これがReviewJobOpeningだったら「もしかしたら、採用担当者が求人をレビューする機能なのかもしれない」と思って見過ごされてしまいかねません。
データモデリング
(省略)データモデルは、システムのデータの関係を書き出す。データモデルは、システムのデータを概要レベルで提供し、データディクショナリは、詳細ビューを提供する。
ソフトウェア要求 第3版 第13章 データ要求の仕様作成 13.1 データ間の関係のモデリング
データモデルを描くのにどの表記法を選択するかは、重要ではない。重要なのは、プロジェクトに参加する全員(理想的には、組織内の全員)が、こうしたモデルを作成するときに同じ表記法を使用し、モデルを使用またはレビューしなければならない全員が、それをどう解釈すればいいかを理解していることである。
ソフトウェア要求 第3版 第13章 データ要求の仕様作成 13.1 データ間の関係のモデリング
データモデリングにはER図またはクラス図を用います。引用の通り、どちらを使うかは重要ではありません。重要なのはあくまで記述する内容であり、その内容が関係者に伝わることです。データモデリングに限らずモデリング手法のアウトプットはビジネスサイドやプロダクトオーナーも閲覧するものです。UMLのような特定の記述方法の知識が乏しい人でも読めるようにするのが望ましいでしょう。そのため、個人的にはER図でCrow’s Foot 記法を用いるのが良いと考えています。初めて触れる人にとっても直感的に理解でき、一度説明を受ければ図の見た目から意味を思い出すことが容易だからです。
データモデルはユースケースごとに必要なデータモデルを考えるとよいです。以下は、「求職者が履歴書を登録する」ユースケースで使われる「履歴書」のデータモデルです。
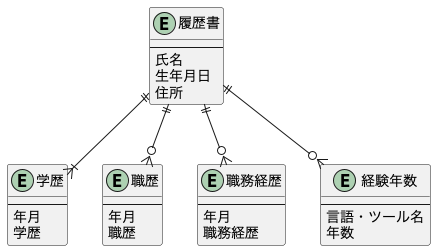
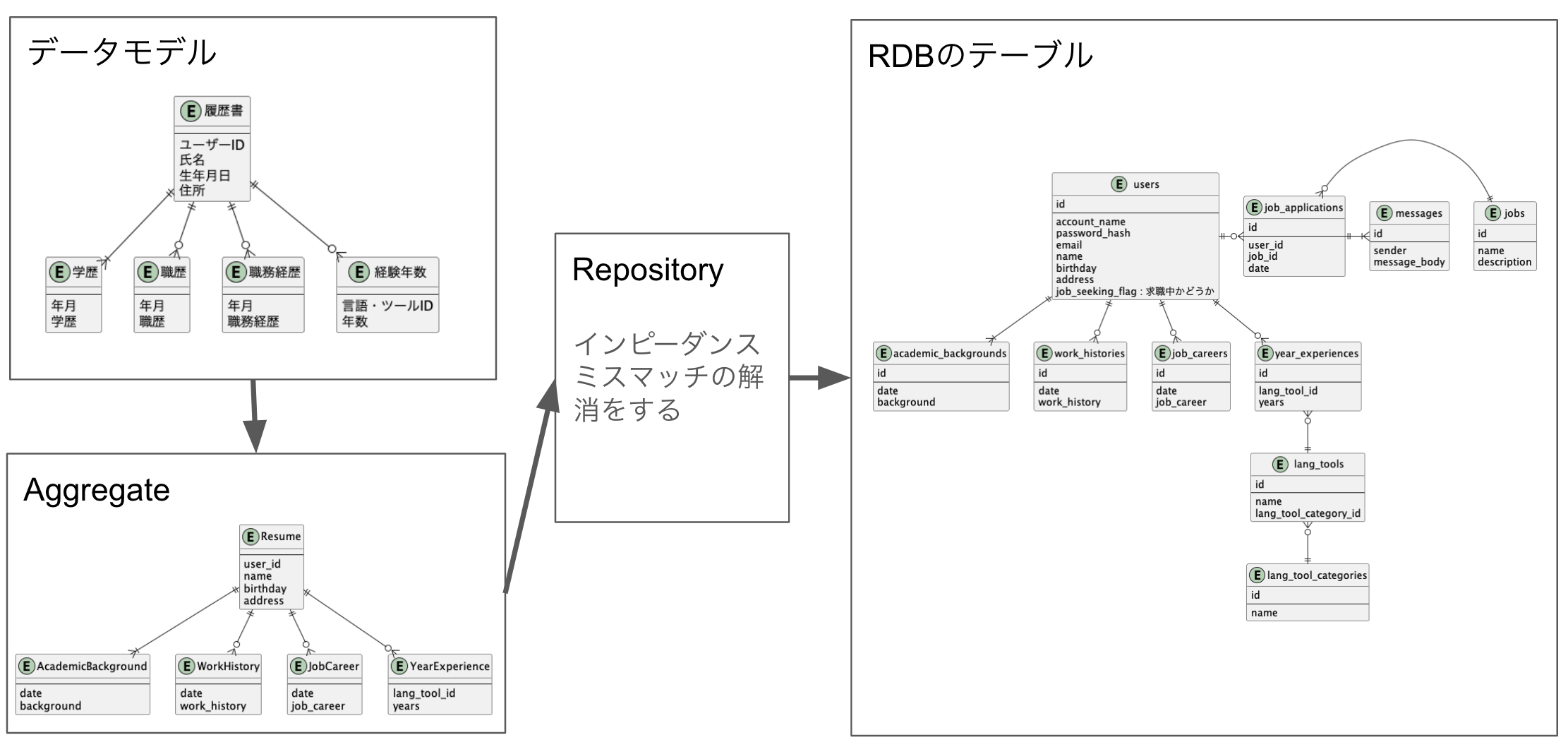
ポイントなのは、RDBのテーブル構造のことは考えていないという点です。上記のER図を元にしたAggregateとRDBのテーブル構造のインピーダンスミスマッチはRepositoryで解消します。つまり、RDBのテーブル設計は別に行う必要があるということです。
また、別のユースケース、例えば「採用担当者が応募を確認する」の場合は以下のような「応募者情報」のデータモデルを考える必要があるでしょう。
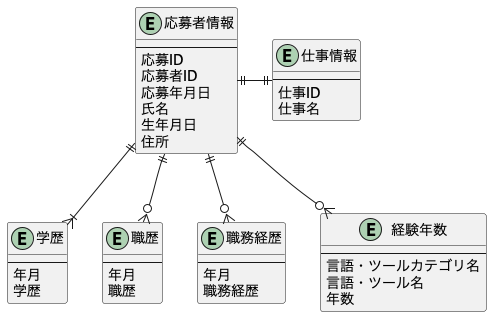
ここで、「履歴書」と「応募者情報」で学歴、職歴、職務経歴は全く同じように見えます。同じなのだから、Aggregateを作る時は同じEntityを使いまわせば良いと考えるかもしれません。しかし、それはお勧めしません。データ構造だけ見ると同じでも役割が異なるからです。仮に実装するなら以下のようになるでしょう。
# 履歴書の職務経歴
class Resume::JobCareer
# attr_readerはgetterを定義するシンタックスシュガー
attr_reader :date, :job_career
def initialize(date, job_career)
@date = date
@job_career = job_career
end
# 職務経歴の本文(job_career)は100文字まで
def valid?
return false if 100 <= @job_career.length
true
end
end
# 応募者情報の職務経歴
class ApplicantInformation::JobCareer
attr_reader :date, :job_career
def initialize(date, job_career)
@date = date
@job_career = job_career
end
end
「履歴書」は「求職者が履歴書を登録する」ユースケースで使われるので、バリデーションの処理が必要になります。それに対して、「採用担当者が応募を確認する」ユースケースの「応募者情報」は表示するだけなので特別な処理が必要ありません。もちろん、表示するだけでも何らかのロジックが必要になることはあります。例えば、ECサイトで「ユーザーが商品を閲覧する」ユースケースで「商品」のAggregateを実装するなら、割引計算後の値段を返すメソッドを定義するといったことをするはずです。
このように、ユースケースごとにAggregateおよびEntityの役割は異なってきます。そのため、データモデルの輪郭が完全に一致していたとしてもユースケースが異なるなら別々のAggregateとして定義することをお勧めします。例外なのは、「ユーザーがブログのエントリを下書き保存する」ユースケース、「ユーザーがブログのエントリを保存する」ユースケースのように本当に実態が同じ場合です。こういう場合は、ユースケースが異なっても同じAggregateを使うという選択肢が出てきます。
データディクショナリ
データディクショナリは、アプリケーションで使用するデータエンティティに関する詳細情報を集めたものである。構成、データ型、許される値などに関する情報を集めて、共有リソースに保管しておくと、データの妥当性確認基準を明確にし、開発者がプログラムを正しく書くのを助け、統合の問題を最小化することができる。
ソフトウェア要求 第3版 第13章 データ要求の仕様作成 13.2 データディクショナリ
データディクショナリは引用の通り以下のような内容をまとめます。特に書式は決まっていませんが表形式でまとめるのが妥当でしょう。
- データ項目名
- 「氏名」や「職務経歴」、「年月」など
- 説明
- データ項目についての端的な説明
- 構成またはデータ型
- 「職務経歴」なら文字列、「年月」なら年と月の2つの数値から構成されるなど
- 長さ、値
- 「職務経歴」なら100文字までとか、「月」なら1から12までと言った制限
データディクショナリでまとめる候補はデータモデリングで定義したER図またはクラス図で定義した属性です。「履歴書」の「氏名」とか「生年月日」をデータ項目としてまとめていきます。場合によっては複数の属性を1つのデータ項目としてまとめるということもありえるでしょう。
重要なのは、データディクショナリでまとめられたデータ項目はValueObjectの候補にはなるが、すべてValueObjectとして作る必要はないということです。前節データモデリングでのコード例のように「職務経歴」の長さチェックをする際にValueObjectを作ることもできますが、このバリデーション処理のためにValueObjectを作るというのは行き過ぎた実装でしょう。
ValueObjectを作った時に一箇所からしか使われず、かつ短い数個のメソッドだけしかないなら、おそらくそれはValueObjectとして実装する価値がないデータ項目です。プリミティブな型(文字列とか数値とか)でEntityのプロパティとして持たせてロジックもEntityのメソッドとして定義したほうが良いでしょう。
ValueObjectとして作る価値があるのは、データ項目としてデータディクショナリに載っていて、なおかつ複数の場所からValueObjectのメソッドが利用される場合か、単一の場所からしか使われないが処理が複雑でロジックをValueObjectの中にカプセル化したい場合です。通常の数値のような四則演算を行うが、通常の数値では処理が煩雑になるような値があるなら、ValueObjectを作成した方が良いでしょう。
ビジネスルール
情報システムの観点から:「ビジネスルールは、ビジネスのある側面の定義または制約を表現したものである。ビジネス構造を確立し、あるいはビジネスの振る舞いを制御または影響しようとする」
ソフトウェア要求 第3版 第9章 ルールに従った行動 9.1 ビジネスルールの分類
ビジネスルールは、何らかの制約や何かを実行するトリガー、何らかの計算ルールなどを文書や数式で表現するものです。ビジネスルールの分類としてファクト、制約、アクションイネーブラ、推論、計算の5つがあります。
- ファクト
- ある時点で真と言えるルール
- 例
- 転職サイトの例: 求職者は無料でシステムを利用できる
- ECサイトの例: 支払い方法は着払い、銀行振込、クレジットカードが利用できる
- 制約
- ユーザーなどが実行できる行動を制限するルール
- 例
- 転職サイトの例: 採用担当者は運営者のレビューを受けなければ求人を公開できない
- ECサイトの例: 合計金額が1500円以下の注文はできない
- アクションイネーブラ
- 何らかの条件が満たされた時に別の何かを実行するトリガーとなるルール
- 例
- 転職サイトの例: 転職後1ヶ月経過したら1万円分のギフト券を求職者に送る
- ECサイトの例: 合計金額が1万円以上の注文は送料が無料になる
- 推論
- 何らかの条件が満たされた時に別の何かが真となるルール
- 例
- 転職サイトの例: 求職者が最後のやり取りから2週間なにもアクションしなかった場合は辞退とみなす
- ECサイトの例: 月間の注文の合計金額が10万円以上のユーザーはプレミアムユーザーとして扱う
- 計算
- 何らかの計算やアルゴリズムなど
- 例
- 転職サイトの例: 履歴書を元におすすめの仕事をレコメンドするアルゴリズム
- ECサイトの例: キャンペーンの割引を適用した価格を計算するロジック
ビジネスルールもデータディクショナリと同じように、Specificationの候補になるがビジネスルールとしてまとめたものを全てSpecificationとして作成するわけではありません。「求職者は無料でシステムを利用できる」のようにコードにしようがないものもありますし、ValueObjectの話と同じようにEntityのメソッドとして定義してしまうのがベターなケースもあります。ValueObjectのメソッドにするケースもあるでしょう。
EntityのクラスをHogeHogeEntityのようにサフィックスをつけるかどうかも好みの別れるところだろうと思います。個人的にはSpecificationにRuleというサフィックスをつける以外にサフィックスをつけることはしていません。ただ、これはDomainServiceとEntity、ValueObjectの区別がつくことが前提です。
すでに書いている通り、Entityは自分の属するAggregateの中以外から依存されるべきではありません。これは逆に言えば、ValueObjectやSpecificationは特定のAggregateに属すわけではないので、複数のAggregateから依存されて良いということです。EntityとValueObjectの区別がつかないなら、この点は大きな問題になりえます。そのため、ValueObjectにValueObjectとサフィックスをつけてEntity特別できるようにしても良いでしょう。
私がSpecificationにRuleとつけているのは、ValueObjectというデータ主体のクラスではなく、ビジネスルールというロジックが主体のクラスであることを明確にする意図によるところです。SpecではなくRuleとしているのは、Rubyの場合はRSpecというデファクトスタンダードなテスティングフレームワークがあり、Specだとそれを想起して紛らわしいためです。
また、RepositoryやFactoryはAggregateの名前に対応した名前をつけることになるため、サフィックスとしてRepositoryやFactoryをつけたほうが望ましいと考えています。
状態遷移図
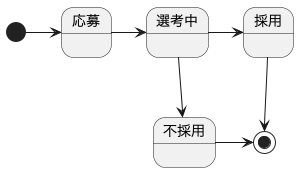
状態遷移図について説明は不要でしょう。見ての通り、どういう状態をたどるかを図で表します。
ポイントなのは、応募から選考中に進むことはできても、選考中から応募中に戻ることはできないという点です。これをコードとして表現しておくことは重要です。というのも、往々にして状態遷移図は作られないか開発が進むにつれて複雑化していって、だれも正確な状態遷移のフローを把握していない事態に陥るからです。
class SelectionProcess
def initialize(current_process)
@current_process = current_process
end
# 状態遷移先として応募に進めるか
def can_to_apply?
false
end
# 状態遷移先として選考中に進めるか
def can_to_selecting
return true if @current_process == 'apply'
true
end
end
このSelectionProcessを分類するならValueObjectになるだろうと思います。
Next はじめに | ドメイン駆動設計ハンズオン