ドメイン駆動設計の戦術的設計とは | これで理解できるドメイン駆動設計!
Prev: ドメイン駆動設計とは
なぜドメイン駆動設計に戦術的設計と呼ばれる設計パターン群があるか
AggregateやEntity、ValueObjectなど戦術的設計と呼ばれるものは、エリック・エヴァンスのドメイン駆動設計では「第2部 モデル駆動設計の構成要素」で出てきます。部のタイトルの通り、モデル駆動設計をする上で使うパターンだということです。
では、モデル駆動設計とは何かというと、作成したモデルが実装に反映されるように設計を行う設計手法です。ドメイン駆動設計はドメインを分析してドメインモデルを明らかにしドメインモデルが実装に反映されるように設計を行う設計手法でした。モデル駆動設計という言葉を使ってドメイン駆動設計を説明するならば、ドメイン駆動設計はモデルをドメインモデルに限定したモデル駆動設計ともいえます。
Aggregate、Entity、ValueObjectなどは、モデル駆動設計を実践、つまりモデルをコードで表現するときにモデルに対応づけて利用できる設計パターンであるということです。
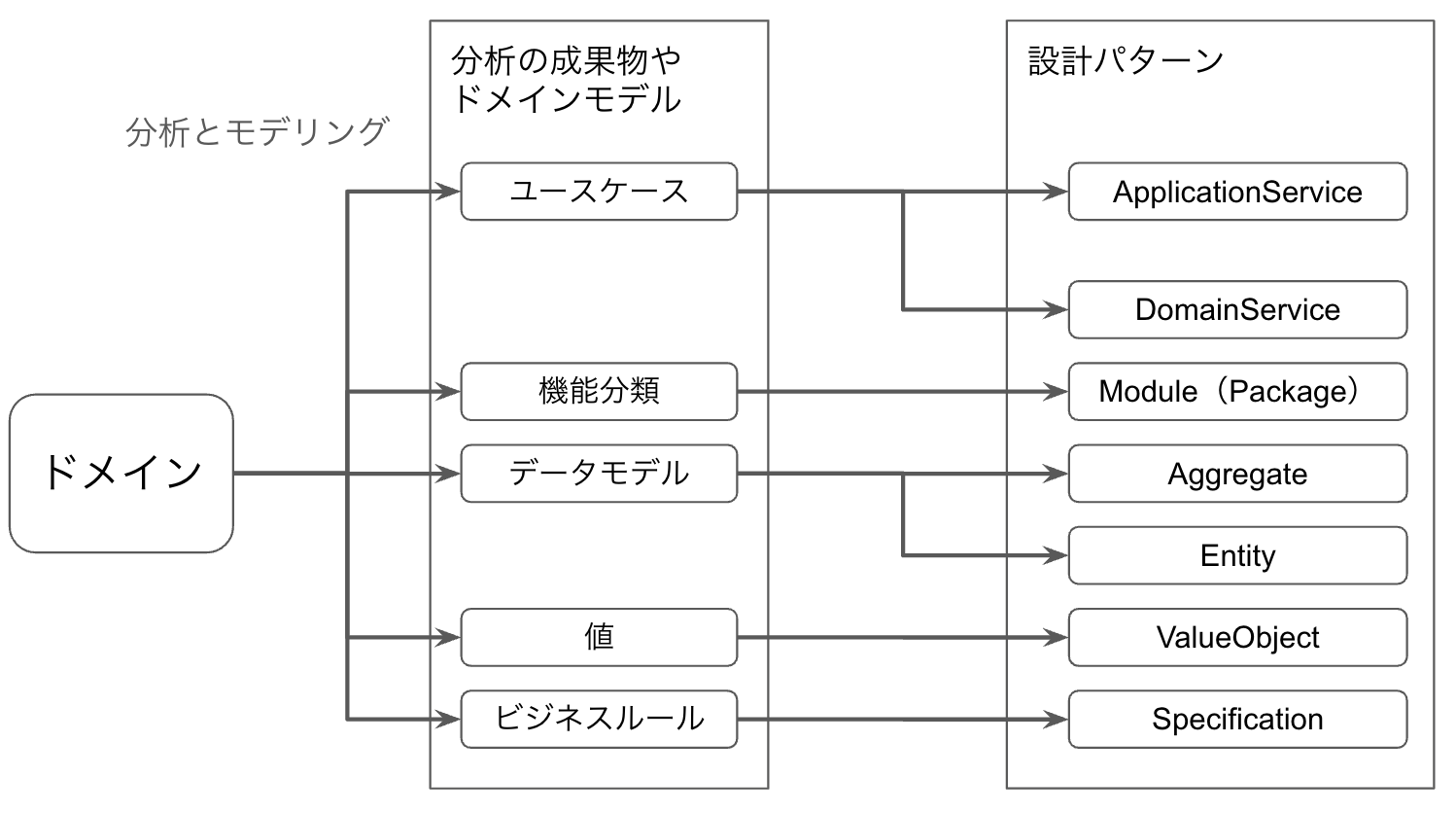
各設計パターンの役割
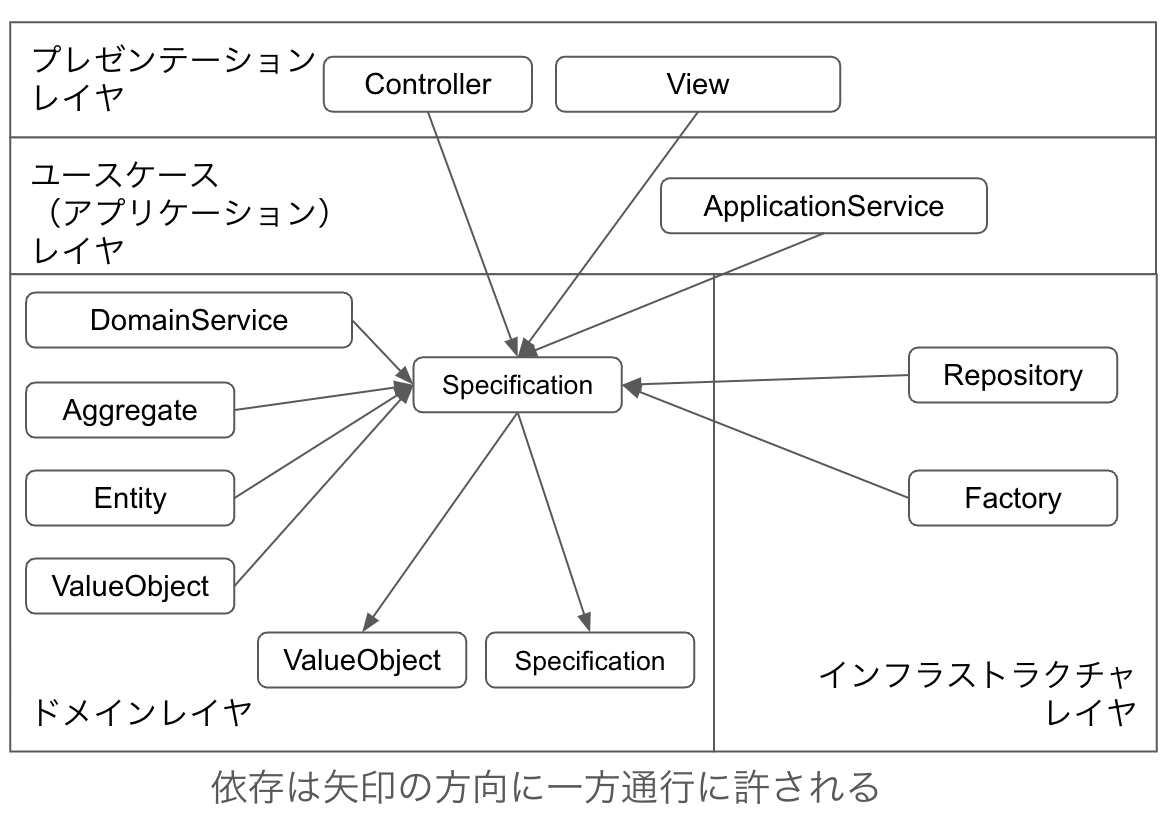
設計パターンは3つに分類できます。それは、「アプリケーションの機能としてのエンドポイント」、「ドメインモデルを表現するもの」、「データの永続化と復元」の3つです。
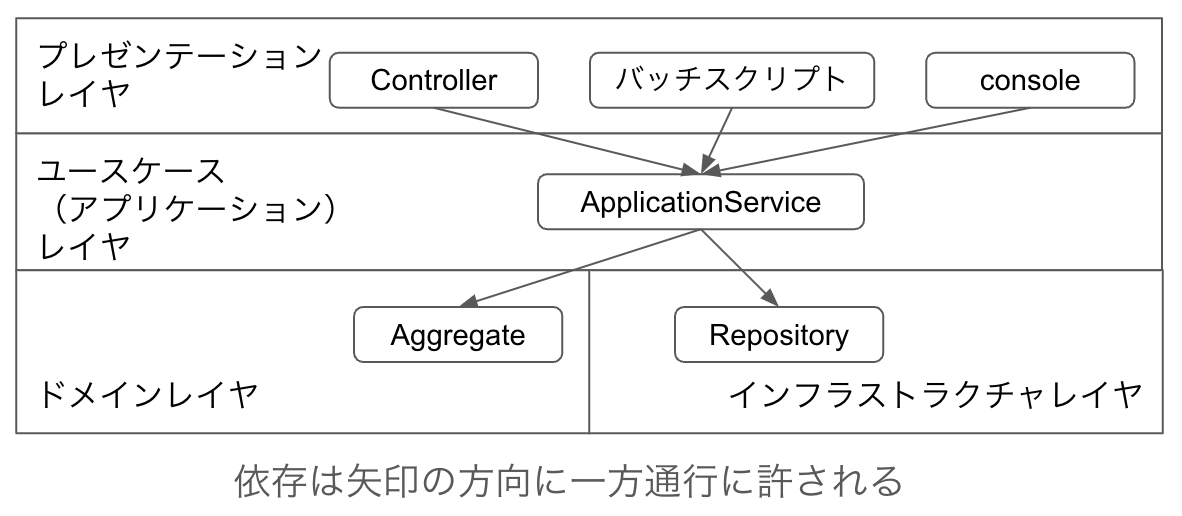
「アプリケーションの機能としてのエンドポイント」に分類されるのはApplicationServiceのみです。ApplicationServiceは機能を実行するときのエンドポイントとして作成されます。エンドポイントというのは、ControllerのActionから呼ばれたり、バッチスクリプトから呼ばれたり、あるいはrails consoleのようなエンジニアが対話的にコードを実行するときに呼ばれたりするポイントを指しています。あくまで、Actionなどから呼ばれるApplicationServiceがエンドポイントであり、Actionなどのことをエンドポイントと言っていません。とはいえ、実際には、いずれか一つからだけというのが大半だろうと思います。rails consoleから呼ばれることを想定していることからもわかる通り、ApplicationServiceのメソッド単体でトランザクションが完結します。
「ドメインモデルを表現するもの」に分類されるのは、DomainService、Module(Package)、Aggregate、Entity、ValueObject、Specificationだけです。これらのクラスを作るのであれば、元となるドメインモデルが必ず存在します。図や文書のドメインモデルをコードで表現したものもまた、ドメインモデルと呼ばれるのですが区別ができないため、ドメインモデルをコードで表現したものはDomainModelと表記します。
「データの永続化と復元」に分類されるのは、ドメイン駆動設計としてはRepositoryとFactoryのみです。これらを作るのであれば対応するAggregateが必ず存在することになります。ドメイン駆動設計とは別の話になりますが、ドメインモデルを受け取ったり生成せずに外部データソース(RDBなど)にアクセスする処理をカプセル化するGatewayも、これに分類されます。
「ドメインモデルを表現するもの」、「データの永続化と復元」に分類されるものは、ApplicationSerivceから利用されます。
また、これらの分類はそのままレイヤ構造に対応します。「アプリケーションの機能としてのエンドポイント」はユースケース(アプリケーション)レイヤ、「ドメインモデルを表現するもの」はドメインレイヤ、「データの永続化と復元」はインフラストラクチャレイヤです。レイヤの話については次章のレイヤとドメイン駆動設計の関係で言及します。
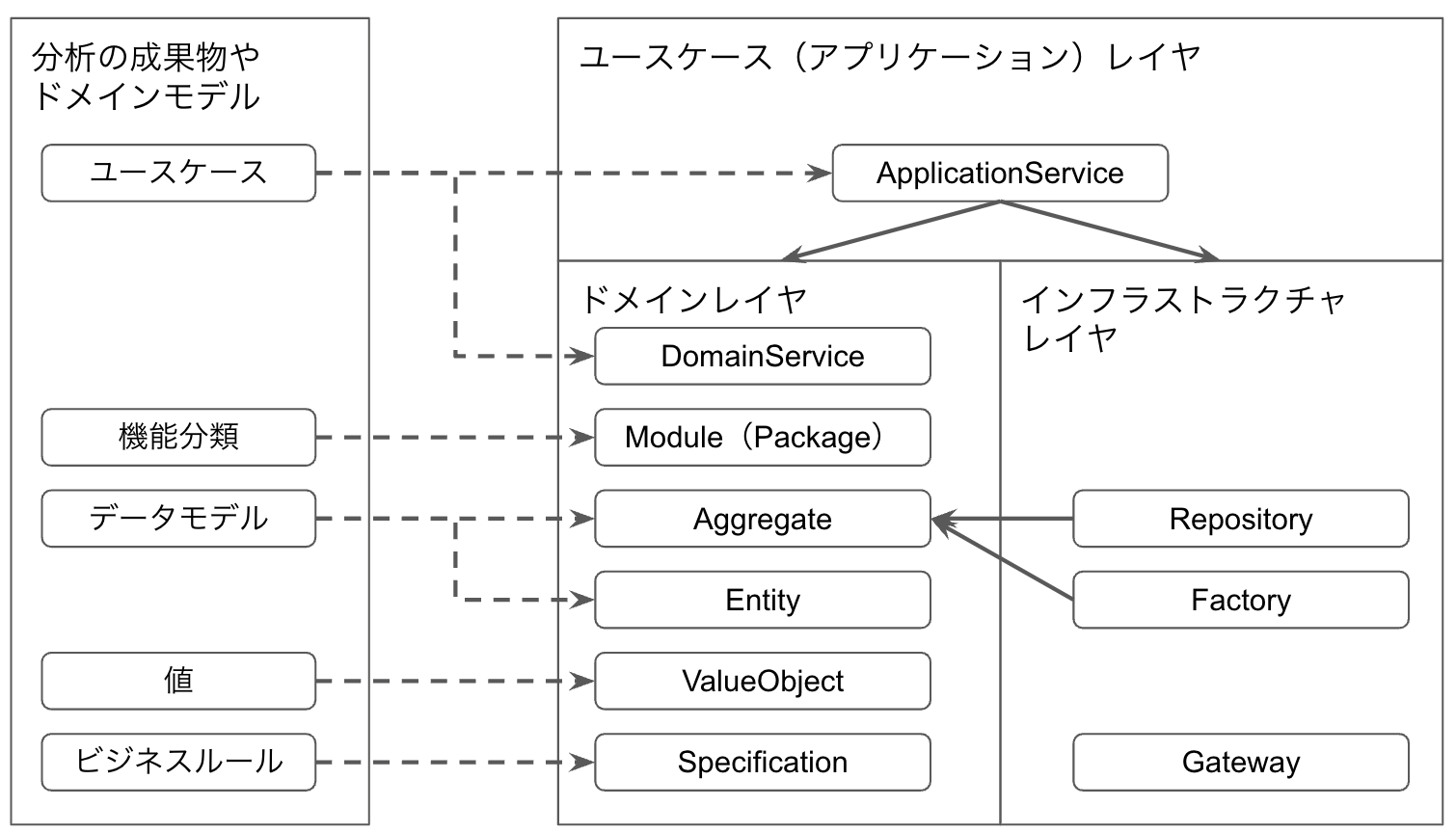
設計パターン群の解説
これ以降、個々の設計パターンの解説に入りますが、要素が多く理解しきれないかと思います。なので、一旦は流し読みして、次章のレイヤとドメイン駆動設計の関係やその次のドメイン駆動設計の核心に進むのもアリかと思います。
ApplicationService
分析結果としてのユースケースやユーザーストーリーに対応する形で作成する設計パターンです。
すでに前節で書いている通り、「アプリケーションの機能としてのエンドポイント」になります。担うことは機能の複雑度によって変わりますが、おおよそ以下の組み合わせになります。
- (DIを行うかはともかくとして)RepositoryやGatewayを用いて外部データソースへのアクセス
- FactoryやRepositoryを使ってDomainModelを生成
- DomainModelを使ってビジネスロジックを実行
- Repositoryを使ってDomainModelの永続化、あるいは、Gatewayを使ってデータの永続化
ミュータブルである必要性は通常ないので、イミュータブルになるようにします。
エンドポイントと書いている通り、アプリケーションの一番外側に位置するため、ドメインレイヤやインフラストラクチャレイヤから依存されることは許されません。ドメインレイヤやインフラストラクチャレイヤに依存する側です。
次章のレイヤとドメイン駆動設計の関係で詳しく言及しますが、DomainModelやRepository、Gatewayを用いないトランザクションスクリプトパターンを実装するのもありだと個人的には考えています。DIについても次章のレイヤとドメイン駆動設計の関係を参照ください。
ユースケース(アプリケーション)レイヤとしての責務はレイヤとドメイン駆動設計の関係を参照ください。
# 管理者がユーザーを削除するユースケース
class AdminDeleteUserUseCase
def initialize(admin)
@actor = admin
end
def perform(user_id)
raise '管理者のみ実行可能' unless admin.admin_user?
user_repository = UserRepository.new
# RepositoryやGatewayを用いて外部データソースへのアクセス
# かつ
# FactoryやRepositoryを使ってDomainModelを生成
user_aggregate = user_repository.find(user_id)
# DomainModelを使ってビジネスロジックを実行
return false unless user_aggregate.can_delete?
# DomainModelを使ってビジネスロジックを実行
user_aggregate.pre_delete
email = user_aggregate.email
# Factoryを使ってDomainModelの永続化
return false unless user_repository.delete(user_aggregate)
# メール送信もGatewayの一種と考えられる
UserMailer.with(email: email).notice_account_deletion.deliver_later
true
end
end
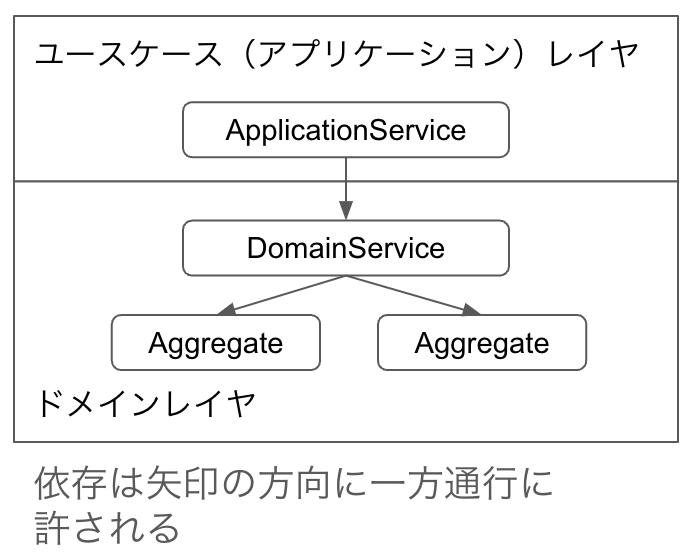
この章では各設計パターンで許される依存関係をまとめています。しかし、丸暗記する必要はありません。理解するべきは各設計パターンの役割です。依存が許される許されないは役割によって決まります。
例えば、ApplicationServiceはアプリケーションのエンドポイントとして機能を実行するのが役割です。エンドポイントですから、アプリケーションのより外側のControllerやバッチスクリプトから呼ばれる、つまりは依存されるわけです。逆に内側のドメインレイヤやインフラストラクチャレイヤから依存されるのはおかしいというわけです。
つまり、各設計パターンの役割さえわかっていれば、許される依存、許されない依存はおのずと見えてきます。また、例外的な型破りが許されるかどうかも判断できるようになるでしょう。
DomainService
分析結果としてのユースケースやユーザーストーリーに対応する形で作成する設計パターンです。
あまり使われないパターンですが、ドメインロジックが複雑だがAggregateなどを作るほどのものではない場合(ドメインロジックのみのトランザクションスクリプトパターン)、複数のAggregateを協調させて複雑なドメインロジックを書く必要がある場合(複数のAggregateに対するFacadeパターン)に作ります。どういうときに作るかを考えるよりかは、ApplicationServiceに置くには複雑なドメインロジックだな、かといってAggregateなどに載せるのも不自然だな、そうだDomainServiceを作ろう! という発想で作るのが良いと考えます。
ミュータブルである必要性は通常ないので、イミュータブルになるようにします。
作成する場合はドメインレイヤの一番外側に位置します。そのため、他のドメインレイヤのクラスから依存されることは許されません。他のドメインレイヤのクラスに依存する側です。ユースケース(アプリケーション)レイヤから依存される側であり依存する側ではありません。インフラストラクチャレイヤから依存されることも許されません。オニオンアーキテクチャなどDIを経由してですが、インフラストラクチャレイヤに依存する考え方もあるようですが、私は避けています。
ドメインレイヤとしての責務はレイヤとドメイン駆動設計の関係を参照ください。
Module(Package)
分析を行う中で、この機能はこういう機能のまとまりに含まれると言った形で階層構造に分類されるはずです。その機能分類の分析結果を元に作成します。
Module(Package)はDomainModelを整理するために作成されます。プログラミング言語によっては単なるディレクトリでしかないこともあるでしょう。
付け加えておくと、Module(Package)に限りませんが、ドメインモデルや他の分析結果は継続的に見直されていきます。Module(Package)などのDomainModelもその見直しに追従するように継続的に見直されていきます。ですので、最初に作ったModule(Package)構造をそのまま維持し続けるわけではないという点には注意してください。
転職サイトを例にするなら以下のような機能分類が考えられます。
- マッチング機能/求職者情報登録機能
- マッチング機能/求人情報機能/下書き登録機能
- マッチング機能/求人情報機能/登録機能
- マッチング機能/求人情報機能/応募終了機能
- 応募採用機能/求職者応募機能
- 応募採用機能/企業スカウト機能
マッチング機能/求人情報機能/登録機能ならmatching/job_opening/ディレクトリを作り求人情報のAggregateをこのディレクトリに格納する形になります。
Aggregate
データモデルで表現したドメインモデルを元に作成する設計パターンです。データモデルの一群のツリー全体がAggregateになります。ツリーの頂点はルートと呼ばれ、このルートのクラスをAggregateと呼ぶこともあるようです。
Aggregateはデータの一貫性を保持する単位です。基本的にAggregateに含まれるルート以外のインスタンスにアクセスできるのはAggregateに含まれるインスタンスだけです。これは、Aggregateの外からルート以外にアクセスできてしまうと、Aggregate全体としての一貫性を保持できなくなってしまう可能性が高いからです。言い換えるとAggregateに含まれるルート以外のインスタンスはカプセル化してルートのメソッドを経由してしかアクセスできないようにします。
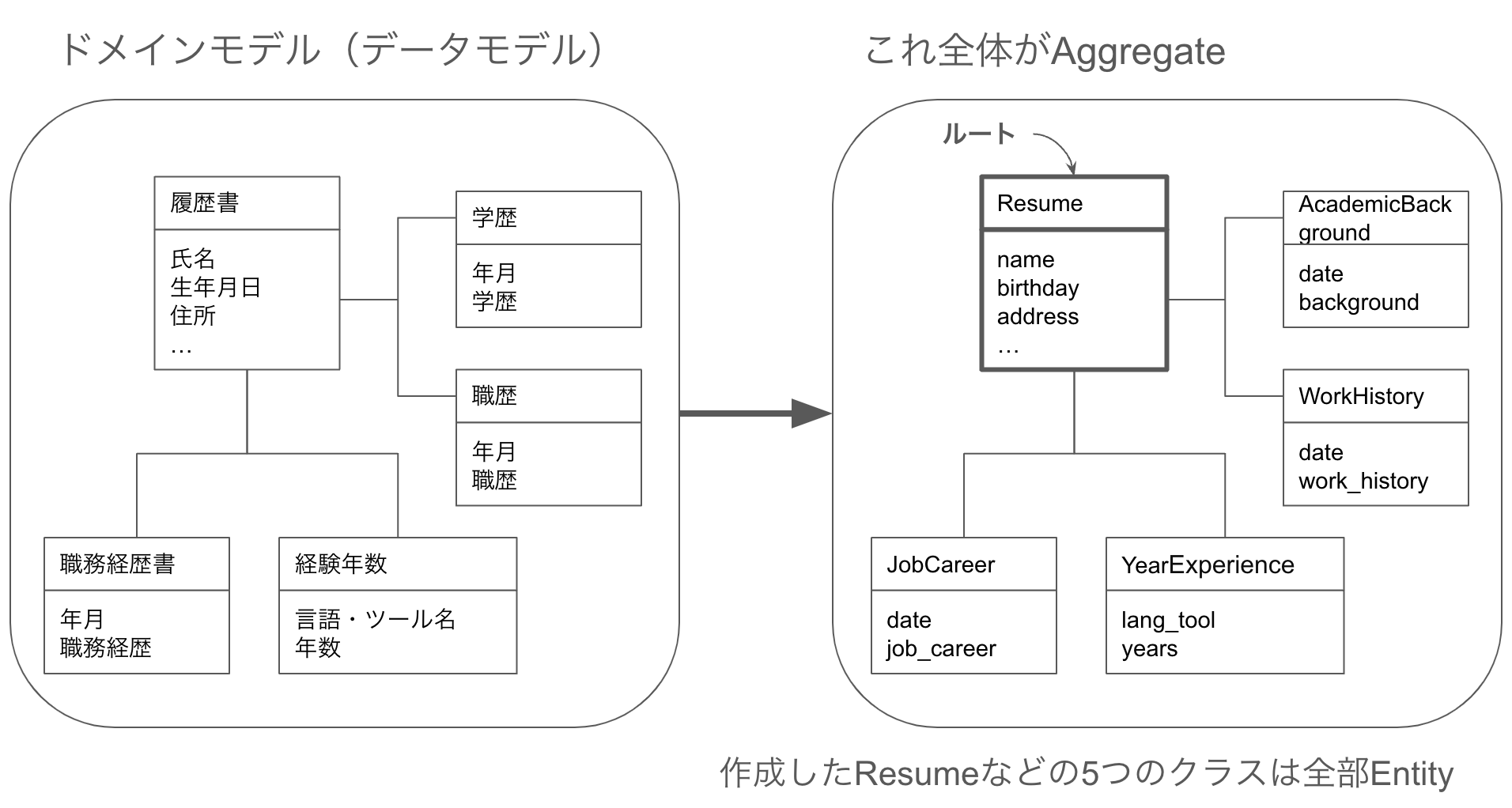
インフラストラクチャレイヤを意識した説明では、DomainModelをデータベースなどから復元したり永続化したりする単位といえます。例えば、履歴書のAggregateを考えてみます。履歴書のAggregateは氏名や生年月日のプロパティに加え、学歴や職歴を持つツリー構造になっています。データベースに履歴書のデータを保存する場合、この一連のツリー構造に含まれるデータが永続化されます。どこの誰とも分からない学歴データだけ保存することは無意味なので、履歴書全体が永続化される単位になるというわけです。Repositoryの説明も参照してください。
更新する場合、学歴データだけ保存することはあるのでは?と思うかもしれません。はい、その場合はそういう用途で学歴のAggregateを用意すれば良いのです。個人的にはお勧めしませんが、履歴書のAggregateを再利用するような1つのドメインモデルを複数の用途で使い回すという考え方もあるようです。詳しくはモデリング手法で言及します。
必要に応じてミュータブルにします。
DomainServiceを作成しない場合はドメインレイヤの一番外側に位置します。そのため、DomainServiceを除いて他のドメインレイヤのクラスから依存されることは許されません。他のドメインレイヤのクラスに依存する側です。ユースケース(アプリケーション)レイヤから依存される側であり依存する側ではありません。インフラストラクチャレイヤへの依存は許されません。インフラストラクチャレイヤはAggregateを生成する役割を担うため、インフラストラクチャから依存されます。他のAggregateから依存されることも依存することも単一責任の原則に違反しないために避けた方が良いはずです。
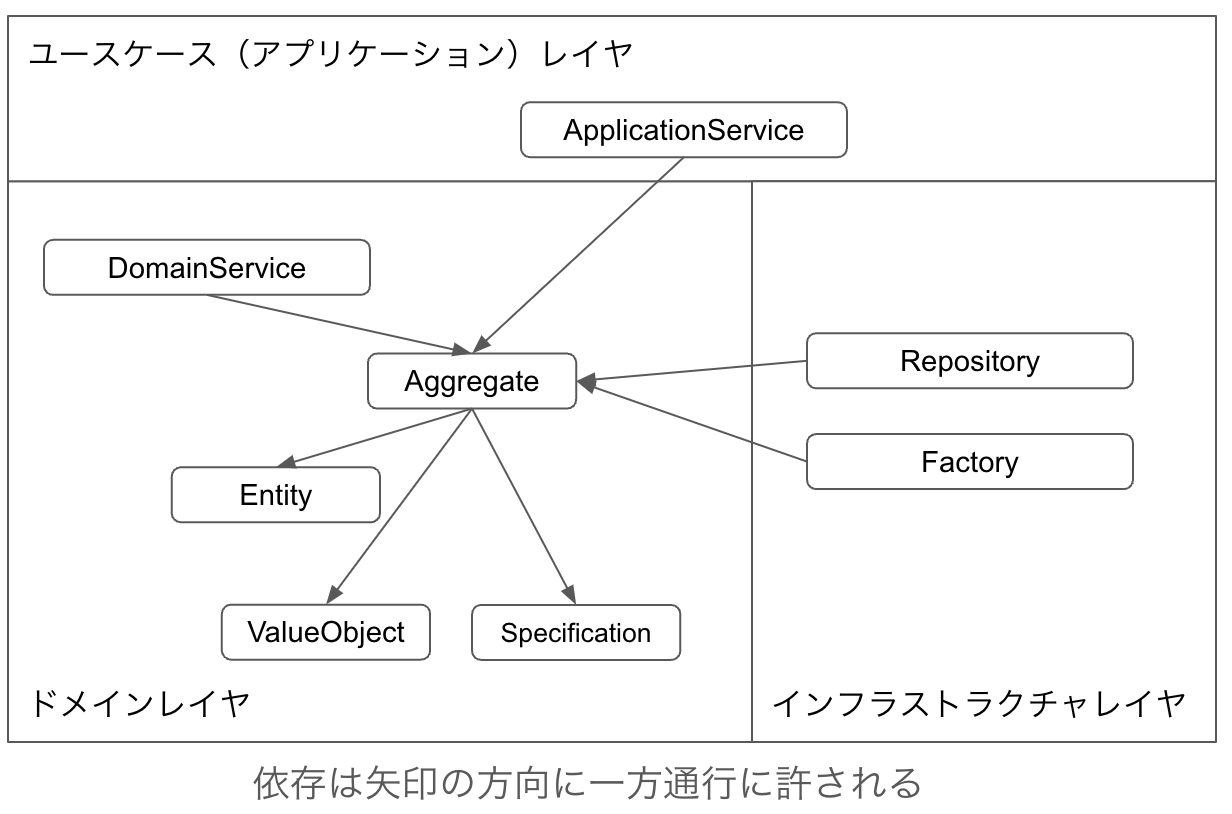
Aggregateの永続化はアトミックな操作です。Aggregateの一部だけが保存されるということは許されません。全部保存されるか、全部保存されないかです。後述しますが、Aggregateの永続化を担うのはRepositoryです。ここまで書くとRepositoryの中でトランザクションを張るのが妥当のように思えます。
しかし、別個のAggregateを複数操作して永続化したいような場合、Repositoryは1つのAggregateに対応するわけですからRepositoryの中でトランザクションを張ると困ったことになります。
xxx_repository = XxxRepository.new
yyy_repository = YyyRepository.new
# 本当はxxx_aggregateとyyy_aggregateを1つのトランザクションで保存したい
xxx_repository.save(xxx_aggregate)
yyy_repository.save(yyy_aggregate)
取れる選択肢は3つあります。
- 同時に操作しようとしているAggregateを統合して1つのAggregateとRepositoryにする
- 何らかの方法で結果整合性が取れるように工夫する
- ApplicationServiceでトランザクションを張って複数のRepository操作を1つのトランザクションにする
1つ目の手段はわかりやすいですが、AggregateやRepositoryの再利用ができないというデメリットがあります。
2つ目の手段は何らかの方法で結果整合性を担保する仕組みを構築する必要があり、オーバーエンジニアリングの可能性が高いでしょう。トランザクションが長時間になるときに解決手段として選択肢に上がるものです。
3つ目の手段が最もわかりやすく単純です。Repositoryを使うApplicationServiceでトランザクションを張ってしまうというものです。
# Railsでのトランザクションの記述方法
# endの行までがトランザクションに含まれる
ActiveRecord::Base.transaction do
xxx_repository.save(xxx_aggregate)
yyy_repository.save(yyy_aggregate)
end
この方法の良いところは、結果整合性を取る形に変えることになったとしてもトランザクションを分割しやすいところです。Repositoryという形ですでに別れていますし、分割ポイントがすべてApplicationServiceの中に列挙されています。
Entity
Entityもデータモデルで表現したドメインモデルを元に作成する設計パターンです。Aggregateはデータモデルの一群のツリー全体に対応しますが、Entityはデータモデルの個々のクラスに対応します。AggregateのルートもまたEntityです。
Entityは何らかの識別子をもち、その識別子のみによってインスタンスが等価か判断される設計パターンです。パターンとしての性質はそれだけです。必要に応じてミュータブルにします。
class FooEntity
attr_reader :id
def initialize(id)
@id = id
end
def ==(other)
@id == other.id
end
end
# 特別なことをしなくてもRubyではobject_id、Javaならメモリアドレスを識別子として使って
# 等価比較が行われるためRubyなら==メソッド、Javaならequalsメソッドを
# オーバーライドしていない限り常にEntityになる
class BarEntity
end
BarEntity.new == BarEntity.new # => false
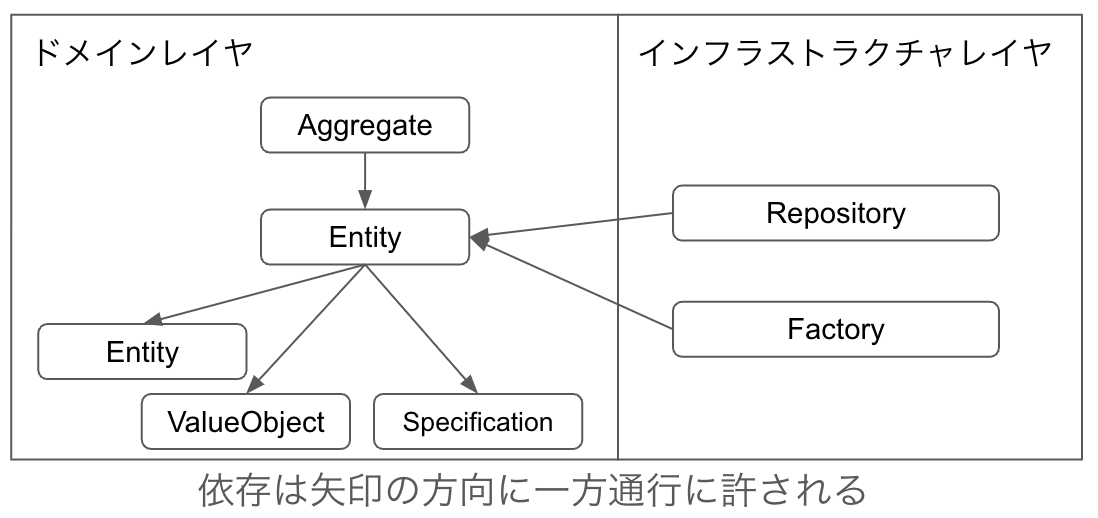
ドメインレイヤ内においては属するAggregateのルートまたは属するAggregateに含まれる他のEntityからのみの依存が許されます。ApplicationServiceとDomainServiceは依存することも依存されることも許されません。ValueObjectとSpecificationは依存する側であり依存されることは許されません。インフラストラクチャレイヤはAggregateを生成する役割を担うため、Aggregateの部品を生成する目的でのみEntityはインフラストラクチャから依存されます。
Entityは特定のAggregateの構成要素なので、そのAggregateのためのデータや処理を持つことになります。そのため、Entityとして実装したクラスを複数のAggregateで共有することは避けた方がよいです。さもないと、複数のAggregateのためのデータや処理を抱えることとなり、単一責任の原則に違反することにつながることになります。
ValueObject
ValueObjectはドメインの中にある値として分析されたドメインモデルを元に作成する設計パターンです。詳しくはモデリング手法で言及しますが、値というのは有理数だったり日付のような同じデータなら交換可能な要素のことです。
設計パターンとしての性質は、持っているメンバ変数が完全に一致した場合にインスタンスが等価と判断されます。パターンとしての性質はそれだけです。基本的にイミュータブルにします。ただ、イミュータブルを維持しようとするとインスタンスの再生成を大量にしてしまうようなエッジケースではミュータブルにするという判断もありえるでしょう。
class DateValueObject
attr_reader :year, :month, :day
def initialize(year, month, day)
@year = year
@month = month
@day = day
end
def ==(other)
@year == other.year && @month == other.month && @day == other.day
end
end
この性質を持つ理由は、ValueObjectが値として振る舞うクラスを実装するパターンだからです。オブジェクトではなく値として認識しているものをいくつか思い浮かべて貰えば、どれも「持っているメンバ変数が完全に一致した場合にインスタンスが等価と判断されている」と気づくでしょう。また、文字列クラスなど一部を除いてイミュータブルなものが多いことにも気づくはずです。
EntityもValueObjectも等価比較の性質に関する設計パターンのため、EntityでなければValueObjectのクラス、ValueObjectでなければEntityのクラスであるということができます。Entityの節で例示したFooEntityのようなEntityでありながらValueObjectでもあるというケース、等価比較時は常にfalseを返すケースといった例外的なケースはいくつか考えられますが、基本的にどちらか一方の性質を持ちます。
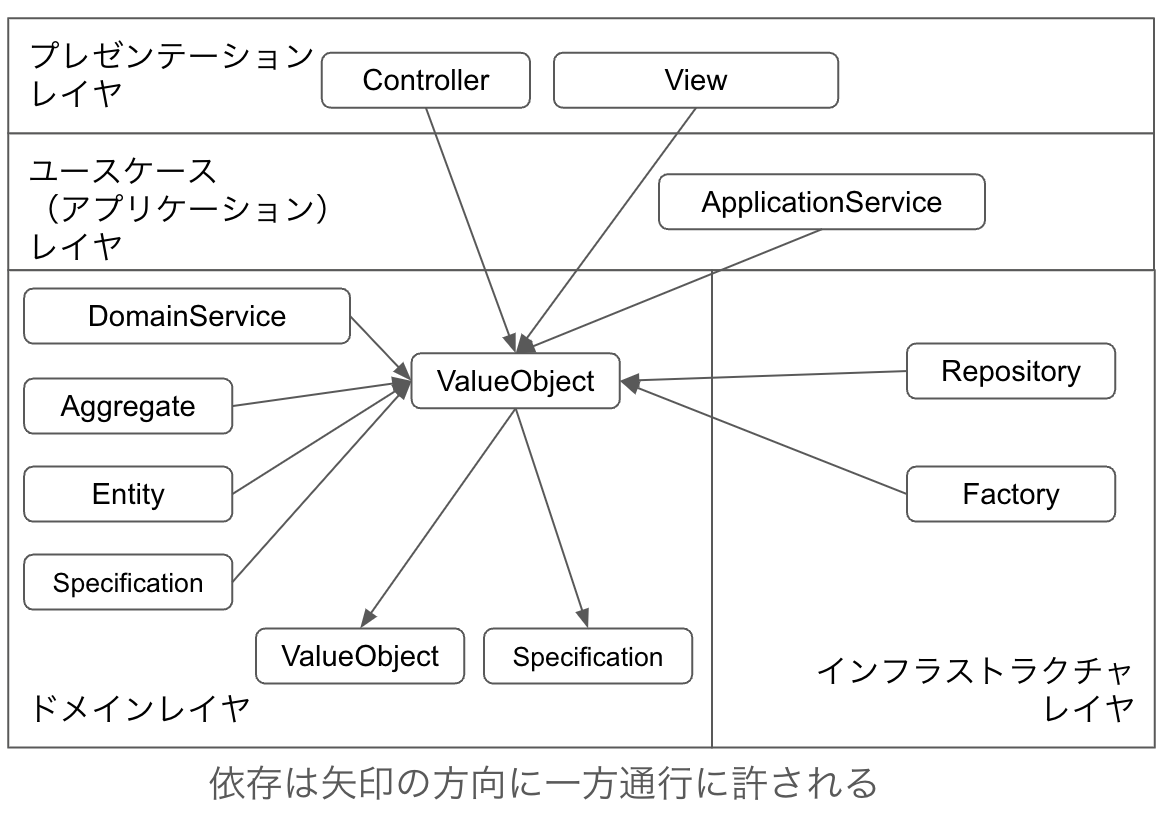
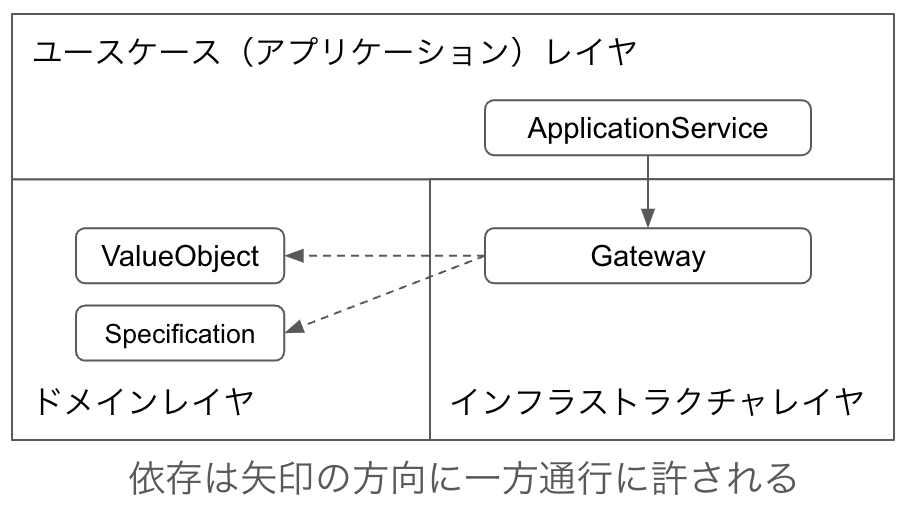
ValueObjectはどこからの依存も許されます。依存できるのは他のValueObjectかSpecificationのみです。
Entityと違って、ValueObjectはAggregateの構成要素として作成されるわけではありません。何らかの値を表現するために作成されるため、その値として振る舞っている限り単一責任の原則に違反することはありません。そのため、複数のAggregateから依存されることを避ける必要はありません。さらにいえば、ViewやControllerから使われることも考えられます。
例えば、お金を表現するValueObjectとしてMoneyクラスを作ったとします。割引計算や消費税計算を行うため内部的には金額を有理数で保持して、金額が必要になったら小数点以下を切り捨てた値を返すクラスです。
# Rationalは有理数のインスタンスを返すメソッド
class Money
# numerator: 分子, denominator: 分母
def initialize(numerator, denominator = 1)
@rational_money = Rational(numerator, denominator)
end
def *(number)
self.class.new(@rational_money * Rational(number))
end
# 現実に利用する小数点以下を切り捨てた金額
def real_money
@rational_money.to_i
end
end
Aggregateの中で利用されるケースは容易に想像できますが、それとは別に、Aggregateを必要としない単にデータベースから取得してきた値を表示するだけの機能で、小数点以下数桁までをデータベースに保存していて、それを表示するようなケースではMoenyクラスが利用できるのは理解できるかと思います。上記は単に小数点以下を切り捨てるだけですが、より複雑な処理を含む場合はViewやControllerから使われることを許す意味は顕著になります。
Specification
ビジネスルールとして分析されたドメインモデルを元に作成する設計パターンです。詳しくはモデリング手法で言及しますが、ビジネスルールというのはドメインの中にある計算式だったり制約などの取り決めなどのことです。
エリック・エヴァンスのドメイン駆動設計においては、検証、選択、要求に応じた構築の3パターンが挙げられており、これらがSpecificationと認識している人もいるようです。しかし、同時に以下のようにも書かれています。
ビジネスルールは、明らかなエンティティや値オブジェクトの責務のどれとも合致しないことがしばしばあり、その多様性と組み合わせによって、ドメインオブジェクトの基本的な意味を圧倒しかねない。しかし、ルールをドメイン層から取り出してしまうのはさらに悪い。ドメインコードがモデルを表現しなくなってしまうからである。
エリック・エヴァンスのドメイン駆動設計 第9章 暗黙的な概念を明示的にする 仕様(SPECIFICATION)
私としては、エリック・エヴァンスのドメイン駆動設計で言及されている3パターンは例示と考え、ビジネスルールを実装する設計パターンと捉えるのが良いと考えています。
設計パターンとしての性質について特にいうことがありません。プロパティではなくロジックが主であるため等価比較されることはまずないですし、ミュータブルにする意味もほぼないでしょう。
Specificationはどこからの依存も許されます。依存できるのは他のSpecificationかValueObjectのみです。
DomainServiceと区別がつかない人がいるかもしれません。DomainServiceはAggregateを使う側で使われる側ではありません。SpecificationはAggregateやEntity、ValueObjectから使われる側です。ValueObjectと同様にSpecificationはViewやControllerから使うことも許されます。
Repository
RepositoryはDomainModelではありません。ドメインレイヤではなくインフラストラクチャレイヤの設計パターンです。
RepositoryはAggregateを受け取ってデータベースなどに永続化する、または、データベースなどからデータを読み取ってAggregateを生成する役割の設計パターンです。従って、対応するAggregateがないのにRepositoryがあるというのはありえません。もし、Aggregateを受け取るでもなく返すわけでもないが、データベースなどにアクセスするクラスがあるなら、それはRepositoryではなくGatewayです。
Repositoryの責務は上記の通りで、言い換えればAggregateというオブジェクトの塊とデータベースなどとの間にあるインピーダンスミスマッチを解消するのが役割です。ここで「データベースなど」としつこく書いていることには理由があります。Repositoryが通信する先はRDBとは限りません。MongoDBやRedisなどのNoSQL、社内にある別サービスのREST API、社外のSaaSサービスのAPIなどもRepositoryが通信する相手となりえます。
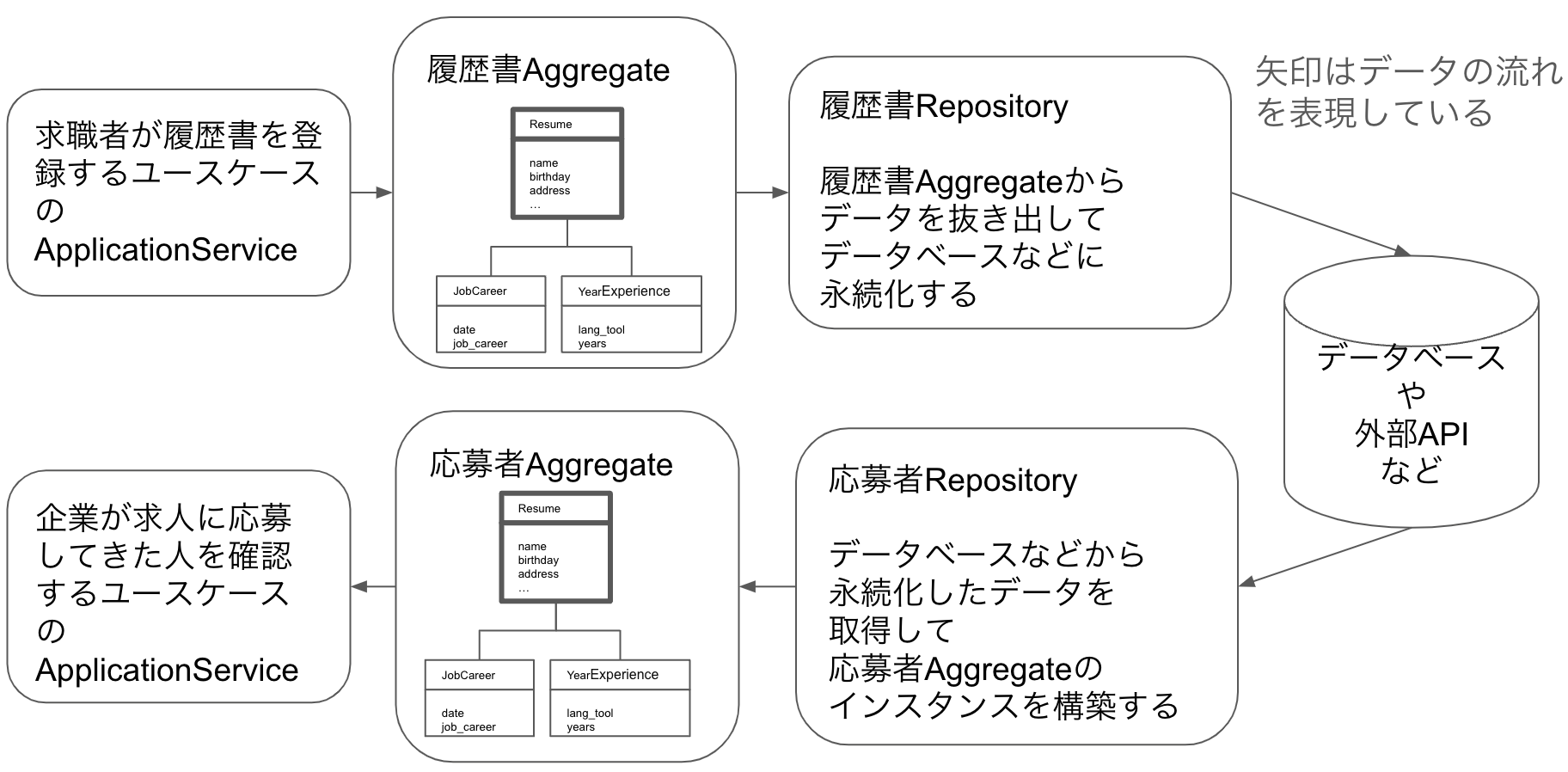
また、AggregateなしにRepositoryは存在しえませんが、RepositoryなしにAggregateが存在するということはありえます。一つはデータベースなどのデータを使わず、ユーザー入力のみで構成されるケースが考えられますが、これはエッジケースです。実際的な話としては、インピーダンスミスマッチの解消が単純なものなら、Repositoryを作らずにApplicationServiceに記述してしまう方法も取れるというものです。
Repositoryの実装は必須ではなく、複雑なインピーダンスミスマッチの解消をカプセル化したかったり、外部APIを叩くゆえにテストのためにDIが必要といった場合に作れば良いパターンです。
イミュータブルかミュータブルかについては、ミュータブルにする意味はないのでイミュータブルにしておけばよいですし、意識せずともイミュータブルな実装になるだろうと思います。
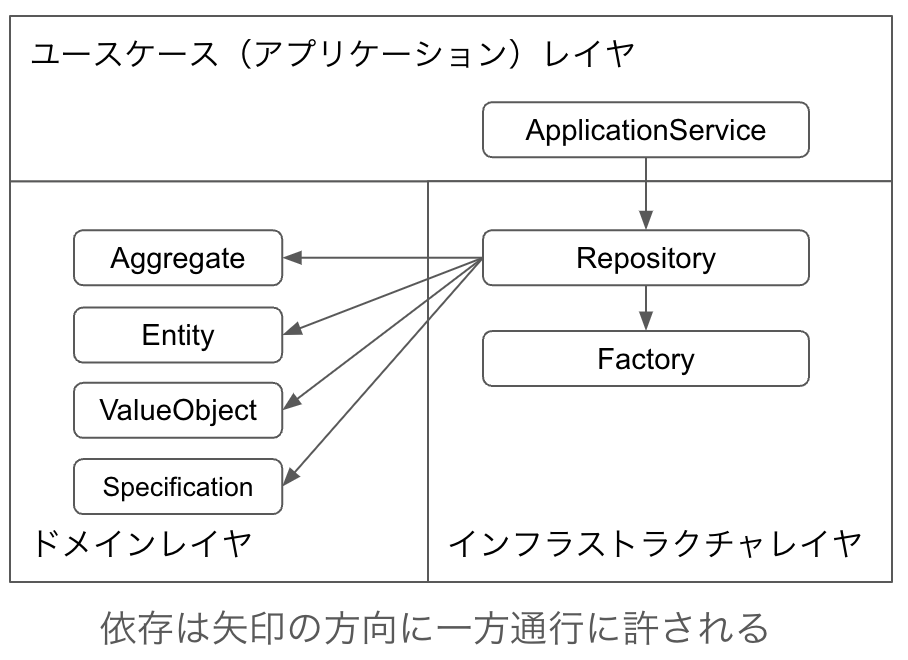
RepositoryはApplicationServiceからのみ依存されます。ApplicationServiceにDIする場合はControllerから依存されることになります。AggregateとEntity、ValueObject、SpecificationはAggregateを構築するために依存しますが依存されることは許されません。ValueObjectとSpecificationの生成はEntityの内部で行なって、Repositoryからの依存はしないという方法も取れます。DomainServiceは依存することは許されません。オニオンアーキテクチャなどDIを経由してですが、インフラストラクチャレイヤに依存する考え方もあるようですが、私は避けています。Factoryは作るなら依存しますが依存されることはありません。GatewayはRepository自身がGatewayの一種なので、依存されることもすることも普通は起きません。他のRepositoryに依存されることも依存することも必要がないはずです。
Factory
FactoryはDomainModelではありません。ドメインレイヤではなくインフラストラクチャレイヤの設計パターンです。
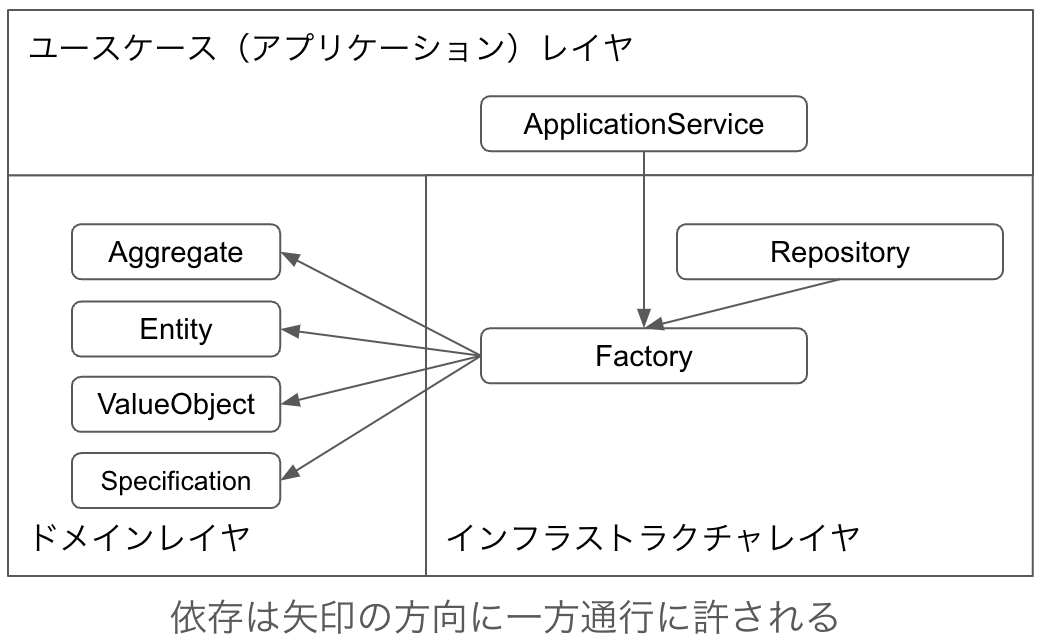
Factoryはデータを受け取ってAggregateを生成する役割の設計パターンです。Repositoryとの違いは、Repositoryはデータベースなどからデータを受け取ってAggregateを生成しますが、Factoryの場合は元となるデータは引数で渡されるだけでしかないという点です。そのため、RepositoryからAggregateの生成部分だけをFactoryとして用意して委譲するということもできます。また、ユーザー入力を元にAggregateを作りたい場合にもFactoryを用意することでAggregateの生成ロジックをカプセル化することができます。
FactoryもRepository同様、必ずしも作られるわけではありません。対応するAggregateがなければFactoryも存在しえません。対応するAggregateがあってもRepositoryやApplicationServiceの中にAggregateの生成処理が組み込まれることもありえます。また、Aggregateや各Entityがコンストラクタで受け取ったデータを元に自身のAggregateを組み上げていくという方法もとることができます。
Factoryがインフラストラクチャレイヤかどうかというのは微妙なところです。プリミティブな値だけを受け取ってAggregateを構築するならインフラストラクチャレイヤである必要はありません。また、AggregateなどがFactoryの役割を担うなら、プリミティブな値だけを受け取るようにした方が良いでしょう。しかし、Factoryがデータベースなどからのレスポンス内容をそのまま受け取って、Aggregateを構築するというやり方も考えられます。この場合はインフラストラクチャレイヤのデータ構造(データベースのレスポンス)に依存している形になるため、インフラストラクチャレイヤにFactoryを置くことが妥当といえます。
私としては、Factoryを作る時はデータベースのレスポンスとAggregateのインピーダンスミスマッチの解消のカプセル化を目的としているので、Factoryがインフラストラクチャレイヤのデータ構造に依存した方がスマートと考えられ、Factoryもインフラストラクチャレイヤにおかれるのは妥当だと考えています。
イミュータブルかミュータブルかについては、ミュータブルにする意味はないのでイミュータブルにしておけばよいですし、意識せずともイミュータブルな実装になるだろうと思います。
クラスとしてFactoryを作ることを前提として依存について説明します。FactoryはRepositoryがあるならRepositoryからのみ依存されます。RepositoryがないならApplicationServiceからのみ依存されます。AggregateとEntity、ValueObject、SpecificationはAggregateを構築するために依存しますが依存されることは許されません。ValueObjectとSpecificationの生成はEntityの内部で行なって、Repositoryからの依存はしないという方法も取れます。DomainServiceは依存することは許されません。オニオンアーキテクチャなどDIを経由してですが、インフラストラクチャレイヤに依存する考え方もあるようですが、私は避けています。Gatewayは依存することはありません。Gatewayから依存されるなら、そのGatewayはGatewayではなくRepositoryになるはずです。他のFactoryに依存する必要はないはずです。
Gateway
GatewayはDomainModelではありません。ドメインレイヤではなくインフラストラクチャレイヤの設計パターンです。また、モデルに関係しない設計パターンであるため、モデル駆動設計で利用できる設計パターンではありません。
Gatewayはデータベースなどにアクセスしてデータを取得したり、データを保存したりする処理をカプセル化するための設計パターンです。RepositoryはGatewayの一種であり、GatewayにAggregateを受け取るまたは返すという制限を加えただけの設計パターンです。
モデルを受け取るでも生成して返すでもない設計パターンなので、実はドメイン駆動設計やモデル駆動設計とは関係のないパターンです。にもかかわらず、あえて紹介しているのは、以下のようなApplicationServiceを実装することがありうるからです。
# 管理者がユーザー一覧を取得するユースケース
class AdminGetUserListUseCase
def initialize(admin)
@actor = admin
end
# conditions: 単に { name: 'suzuki' }のような条件のハッシュ
def perform(conditions)
# 検索条件の組み立ては複雑だが結果は
# [ { id: 1, name: 'suzuki', age: 20 ...}, ...]
# のようなハッシュの配列が返るだけ
UserListGateway.new.search(conditions)
end
end
これをわざわざAggregateを用意してRepositoryでAggregateを生成するように処理を書くことはできるのですが、およそ無駄であることは自明でしょう。次章のレイヤとドメイン駆動設計の関係でも言及しますが、省略して問題が起きないなら省略してしまうのが真っ当な設計というものです。上記のUserListGatewayも単純なデータベースアクセスのロジックならUserListGatewayクラスすら用意せずに、AdminGetUserListUseCaseの中のメソッドにベタベタとデータベースアクセスライブラリ(RailsならActiveRecordのこと)のコードを書いてしまうのも筋の通った選択です。
GatewayはApplicationServiceからのみ依存が許されます。ValueObjectとSpecification以外に依存することは許されません。ValueObjectとSpecificationも通常は依存することはないため、Gatewayは何にも依存しないと理解して良いでしょう。
まとめ
以下の設計パターンは元となる分析の成果物やドメインモデルが存在します。
- ユースケース(アプリケーション)レイヤ
- ApplicationService
- ドメインレイヤ
- DomainService
- Aggregate
- Entity
- ValueObject
- Specification
以下の設計パターンは対応するAggregateが必ずあります。しかし、Aggregateがあるからといって必ず作成するわけではありません。
- インフラストラクチャレイヤ
- Repository
- Factory
各設計パターンには役割があります。役割に基づいて各設計パターン同士の依存関係が構築されます。
Next: レイヤとドメイン駆動設計の関係
日本のドメイン駆動設計界隈では、ValueObjectについて
- 値をクラスで表現するパターン
- プリミティブ型ではなく固有型を作ることでタイプセーフになる
- コンストラクタでフィールド値をチェックすることで不正な値が入らないようになる
- あらゆる値をValueObjectにすることで安全になる
- あらゆるValueObjectはドメインオブジェクトである
- 上記のいずれかを論拠として可読性やメンセナンス性が上がる
というようなことを主張し、これがValueObjectのパターンとしての性質であると主張する人々がいます。
しかし、これらは本来のValueObjectの説明ではありません。ValueObjectに言及している以下の文献のいずれにも、ValueObjectの要件であるとか性質であると説明しているものはありません。
むしろ「あらゆる値をValueObjectにすることで安全になる」については、以下のように諌めている文献すらあります。
そのシンプルな属性が単体で、意味のある全体を成している。それなのに、その属性単体を値型でラップしてしまうという「間違い」を犯してしまいかねない。特別な機能を何も持たないそんな値型を作るなら、値を一切作らないほうがまだマシだ。
実践ドメイン駆動設計 第6章 値オブジェクト 6.1 値の特徴 コラム-すべての道は値オブジェクトに通ず?
また、「コンストラクタでフィールド値をチェックすることで不正な値が入らないようになる」については、実践ドメイン駆動設計でValueObjectの実装の説明の部分で以下のようにガードについて言及したのを曲解した結果である可能性が高いでしょう。
ガードは、どんなメソッドにも仕込むことができる。何らかの方法でパラメータの妥当性を保証しておかないと、あとで深刻な問題が発生するようなメソッドなら、ガードを用意しておくべきだ。
実践ドメイン駆動設計 第6章 値オブジェクト 6.5 実装
同書では、第5章 エンティティ 5.3 エンティティおよびその特性の発見 でEntityに対してガードを用いる例が書かれており、その点からもValueObjectの性質であるかのような説明は間違いであるといえます。
ValueObjectは単に値として振る舞うクラスを実装するパターンでしかありません。
はて、私は何のコラムを書いているんでしたっけ? ああそうでした、このコラムのタイトルは「ドメインモデルとの対応と依存以外のEntityとValueObjectに関する話は忘れて良い」でしたね。
EntityとValueObjectの等価比較の性質にせよ、日本のドメイン駆動設計界隈の人々がいうことにせよ、私は忘れて良いと思っています。
第一に質問です。EntityやValueObjectの等価比較の性質を実現するために等価比較のメソッドをオーバーライドすることが必要になりますが、あなたはそのメソッドは使うでしょうか? 日本のドメイン駆動設計界隈の人々に従ったら喧伝するメリットをあなたは本当に享受できるのでしょうか? 実装することのコスト(コーディングのコスト、ガード処理によるコード量の増加、大量にクラスが作られることによるコードの複雑化、インスタンス生成とガード処理によるパフォーマンス影響など)をペイできるメリットをあなたは享受できるでしょうか? おそらく…… NO ではないでしょうか?
第二に問います。等価比較が必要になったら、そのとき必要な等価比較メソッドを実装すればいいと思いませんか? ガードも契約による設計を理解していれば、実装するのが適切だと判断したときにガードを実装すればいいと思いませんか? 過剰な防御的プログラミングは慎むべきであり、実装コストや可読性、間違いを犯した時のクリティカルさによって必要に応じて行うものだと思いませんか? おそらく…… YES ではないでしょうか?
あなたがポイントを抑えて適切な判断のできるエンジニアであると期待して書きますが、その時々で適切な判断をして適切な実装ができるならEntityとValueObjectの等価比較の性質にせよ、日本のドメイン駆動設計界隈の人々がいうことにせよ、忘れて良いのです。
ただ、ドメインモデルとの対応と依存の話は覚えておくべきです。Entityはデータモデルで表現したドメインモデルを元に作成し、ValueObjectはドメインの中にある値として分析されたドメインモデルを元に作成します。Entityは属するAggregate以外から依存されないようにすること、ValueObjectとSpecificationはあらゆるところから依存されて良いこと、これは忘れないようにしてください。
Next: レイヤとドメイン駆動設計の関係